인프콘 2023 - INFCON 2023 (inflearn.com)
인프콘 2023 - INFCON 2023
인프런이 만드는 IT인의 축제, 인프콘으로 초대합니다. 인프콘과 함께 배우고 나누고 성장하세요. 다양한 발표 세션, 핸즈온, 네트워킹까지 만나보세요.
inflearn.com
오프라인 행사에 참여하고 싶었지만 일정상 참여하지 못했다. 마침 온라인으로도 공개가 될 것이라 하여 잠자코 기다리고 있기로 했다.
한 달 가량 뒤에 온라인 세션이 공개되었는데 생각보다 늦게 공개된 것 같았다. (많이 기다렸다.)
한 달 전에 오프라인 행사 때는 간단하게만 세션을 살펴봐서 이번에 무슨 세션을 들어볼까하고 찾아봤다. 생각보다 전체 세션 수도 많았고 들어보고 싶은 세션 수도 많았다. 총 23개 세션을 듣느라 너무 오래 걸렸다.
오프라인 행사에 참여했어도 많이 듣지 못했을텐데 사람도 많았을 거라 더 듣지 못했을 것 같다. 온라인이 이런 점에서는 속편할 수도 있을 것 같다.
들었던 세션들에서는 도움이 될만한 내용들이 많았다. 가볍게 듣기 좋은 세션도 많았고, 알고 있던 내용들을 회사에 적용하면서 겪었던 경험들도 들을 수 있었고, 몰랐던 정보들(특히 관리자 입장에서의 업무 및 정보)도 많이 들을 수 있었다.
찾아보니 인프콘 2022도 인프런에 올라와있던데 이렇게 내용이 많은 콘퍼런스를 무료로 공유해준 것에 무한한 감사를..
따지면 올해 첫 번째 들은 콘퍼런스였다. 사실 두 번째이기는 한데 첫 번째 콘퍼런스는 작년 콘퍼런스를 올해 초에 들었던 것이다.
이제 10월부터 국내 많은 기업에서 콘퍼런스들을 할 것 같은데 열심히 들어봐야겠다.
아래는 이번 인프콘 2023에서 들었던 세션이다. 아래에 세션별로 내용들을 기록하느라 포스트 글이 많이 길다.
- 소프트웨어 설계를 위한 추성적, 구조적 사고 - 이선협
- 코프링 프로젝트 투입 일주일 전: 주니어 개발자의 코틀린 도입 이야기 - 이석재
- 구글 Apps Script와 ChatGPT로 많은 동료들 생산성 향상 시킨 썰 - 송요창
- 지속 가능한 소프트웨어 개발을 위한 경험과 통찰 - 백명석
- 출시 3일만에 앱스토어 2위를 달성한 사이드 프로젝트 - Skrr(김현준, 김아인)
- 2곳 중 1곳은 무조건 합격하는 개발자 이력서 만들기 - 지소라
- 인프런 아키텍처 2023~2024 - 이동욱
- 오늘도 여러분의 API는 안녕하신가요?: API First Design과 CodeGen 활용하기 - 김정규
- 커뮤니케이션 잘하는 개발자의 4가지 습관 - 송범근
- 변별력을 200% 더 높인 개발자 채용 방법: 코드 리뷰 테스트 - 전종욱
- 안타깝게도 오늘의 TDD는 실패한 것 같군요. 내일은 가능할지도...? - 한윤석
- 왜 내가 만든 서비스는 아무도 안 쓰지?: 개발자가 알아두면 좋은 사이드 프로젝트 제작 팁 - 이동훈
- 왜 구글 시니어 개발자는 코딩을 안할까? - 이다니엘
- 절반의 성공, 마이크로 서비스 아키텍처 도입과 조직 구조 - 서주은
- 어느 날 고민 많은 주니어 개발자가 찾아왔다 2탄: 주니어 시절 성장과 고민들 - 김영한
- 그 많던 코드는 누가 다 먹었을까: Kotlin multiplatform을 활용한 서비스 런칭기 - 최근호
- 점진적 추상화 - 이승천
- 인프런에서는 수천 개의 테스트 코드를 이렇게 다루고 있어요 - 이민우
- 팀플레이어 101: 팀의 성공을 위해 달리는 메이커 되기 - 진유림
- 함수형 프로그래밍 3대장 경험기: 클로저, 스칼라, 하스켈 - 김대현
- 우리는 이렇게 모듈을 나눴어요: 멀티 모듈을 설계하는 또 다른 관점! - 조민규
- 시니어 개발자 너머의 성장: 대규모 조직을 위한 스태프 엔지니어(Staff Engineer) - 남상수
- 패션 이커머스 서비스의 아키텍처 성장 기록 - 이희창
소프트웨어 설계를 위한 추성적, 구조적 사고 - 이선협
문제 해결을 위한 프로세스는 4 단계로 구성되어있다. 문제 이해 및 분석, 설계, 구현, 평가로 구분된다. 이 4 단계를 다시 크게 2 가지로 묶어서 과정을 분류할 수 있다. 문제 이해 및 분석에서 설계까지는 문제를 파악하고 컴퓨터 시스템에 적합하게 설계하는 과정이다. 다시 설계부터 구현, 평가까지는 컴퓨터 시스템으로 전산화 하는 과정이다. 개발자는 실제로 이 모든 영역에 걸친 업무를 수행해야 한다. 특히 시니어 개발자가 될 수록 책임과 범위가 늘어난다.

시니어는 풍부한 경험과 직관이 쌓인다. 하지만 이것만으로 모든 경험해보지 못한 새로운 문제를 해결할 수는 없다. 따라서 우리는 어떤 문제라도 유연하게 해결할 수 있는 시니어가 되어야 한다. 이때 유연하게 해결할 수 있는 추상적이고 구조적인 방법론을 익히는 것이 중요하다.
추상이란 여러 사물이나 개념에서 공통되는 특성이나 속성을 추출하는 것을 말한다. 즉, 추상은 대상을 단순화하고 재해석하는 것이다. 이때 단순화 과정은 무의미할 정도로 과도하게 하는 것이 아니라 의미를 갖는 수준에서의 결합도 필요하다. 과도한 추상화는 화석만 보고 공룡의 실체를 파악하는 것처럼 정확한 모습과 의도를 파악할 수 없게 만든다.
구조적 사고란 내용을 겹치지 않고 빈틈없이 정리하는 것이다. 이러한 방법론은 비즈니스를 위한 MECE(Mutually Exclusive, Collectively Exhaustive) 프레임워크에 자세히 나와있다. 요소들이 중복되지 않고 서로 베타적이어야 됨을 말한다. 이때 중요한건 '빈틈없이' 보다는 '어떻게 나누고 채울 것인가'다.
실제 업무에서 적용하는 구체적인 방법으로는 탑다운(Top-Down)과 바텀업(Buttom-Up) 방식으로 나뉜다. 탑다운의 경우에는 작은 문제들에 대해 잘 모를때 사용하기 좋은 하향식 접근법이다. 버텀업은 세부적인 문제 해결을 통해 전체 문제의 답을 자연스럽게 찾는 상향식 접근법이다. 이 두 방식은 상호 배타적이지 않고 상호 보완적이다.
모델은 세상을 표현하는 방식이다. 모델링의 분식은 분류(Classification), 추상화(Abstraction), 일반화(Generalization)로 나눌 수 있다. 모델링을 할 때 추상화와 구조화는 동시에 일어난다. 추상화는 필요한 요소를 추출하는 것이고, 구조화는 필요한 요소가 겹치지 않고 요구사항을 만족할 수 있도록 배치하는 것이다. 대표적인 예로 OSI-7 layer가 있다.
소프트웨어 설계를 살펴보자. 먼저, 구현 단계를 세 단계로 나눠본다면 도메인 모델링, 아키텍처, 코드 작성으로 나눌 수 있다.
도메인은 우리가 해결할 실생활의 문제의 비즈니스적인 지식을 말한다. 따라서 도메인 모델링은 비즈니스를 개발세계의 언어로 프로그램적으로 표현하는 것을 말한다. 도메인 모델링은 단계적으로 추상화가 가능하다. 가장 추상적인 단계에서부터 점차 요구사항이 명확해지도록 도메인 모델링을 수행할 수 있다. 이런 구체화 과정을 통해 실제 코드에서는 데이터 속성과 함수로 행위를 표현하는 것까지 가능해진다.
도메인 모델은 항상 변할 수 있다. 기존 요구사항에서 모델이 점차 추가되고 모델 사이 관계가 변화할 수 있다. 이런 변화도 결과적으로 코드에 직접 반영될 수 있게 된다.
아키텍처는 일을 하는 방법으로, 소프트웨어를 '어떻게 만드는가'와 '어떻게 나누는가'를 다룬다. 아키텍처는 요구사항과 조직으로부터 큰 영향을 받는다. 컨셉 아키텍처는 추상화된 시스템을 나타낸다. 소프트웨어 특성과 종류에 따라 크게 달라진다. 아키텍처의 컨셉을 알았다면 구현 아키텍처를 구체화한다. 이때 비즈니스 요구사항과 조직의 상황을 고려한다. 여기서는 하향식으로 구체화하는 것이 좋다. 성능과 기술 스택을 고려하고, 조직의 상황에 따라 설계하는 과정을 거친다.
리팩토링은 기능을 수정하지 않고 코드를 개선하는 것을 말한다. 발표자는 주로 6가지 관점에서 살펴본다. 패러다임, 코드 크기, 소유권, 중복 여부, 수정 가능성, 의존성 6가지 항목이다. 이 관점에 따라 세 가지 리팩토링 방법이 존재한다. 모델링과 동일하게 추상화, 구조화, 일반화 방법이다. 추상화는 코드를 숨길 것인지에 대한 것이며, 기능의 변경 가능성이 적고 이해하기 쉬운 코드라면 숨기는 것이 좋다. 구조화는 코드 내용을 분리할 것인지 합칠 것인지에 대한 것이며, 수정 가능성을 따져봐야 한다. 보통 자주 수정이 발생할만한 코드를 분리한다. 일반화는 공통된 코드를 분리하거나 의도적으로 중복시키는 것을 말한다.
추상적이고 구조적인 사고력을 기르기 위한 학습법에는 따로 정답은 없다. 평소 여러 관점으로 바라보는 것이 중요하다. 그러기 위해서 다양한 경험을 하고 다양한 지식을 쌓는 것이 도움이 된다. 개발자라면 도식화를 하면서 생각을 해보는 것도 도움이 된다. UML을 사용해보는 것이 좋은 경험이 될 것이다.
마지막으로 추상적이고 구조적인 것이 항상 좋은 것은 아니다. 때로 두괄식보다 미괄식이 좋을 수 있다.
코프링 프로젝트 투입 일주일 전: 주니어 개발자의 코틀린 도입 이야기 - 이석재
이번 세션에서는 코프링을 도입하면서 조사했던 내용들과 코틀린 학습법, 개발 팁을 포함해 신규 프로젝트에서 고려해볼만한 여러 도구들을 소개한다. 추가적으로 주니어 개발자가 팀에 새로운 기술을 도입하고 전파하면서 겪은 에피소드를 공유한다. 세션의 대상자들은 스프링을 쓰고 있으면서 코틀린에 관심이 있는 개발자, 그리고 팀에 새로운 기술 도입을 설득하고 싶은 개발자다. 그래서 나는 스프링과 스프링 부트에 대한 개념이 없기 때문에 세션 이해에 조금 더 어려움이 있다.
자바와 스프링을 쓰는 팀의 신입 서버 개발자로 입사했으나 코틀린에 관심이 생겨 코프링을 도입하고자 했다고 한다. 처음에는 자바로도 충분하다고 생각되며 코틀린을 위해 추가 플러그인이 필요한 점에서 회의적이었으나 최근 기업 기술 블로그에서 코틀린 포스트가 많아지며 관심이 갔다. 게다가 여러 자바 오픈소스에서도 코틀린을 지원하기 시작했다.
코틀린을 하면서 도움이 되었던 내용들은 다음과 같다.
- Kotlin Koans : JetBrains에서 제공하는 코틀린 학습 프로그램으로, 과제 형식으로 자연스럽게 학습이 가능하다.
- 이펙티브 코틀린(Effective Kotlin) : 약간의 난이도가 있는 코틀린 서적이다. 어느정도 기본 문법은 알고 보는 것을 추천한다.
- 공식 문서 : 코틀린 공식 문서는 읽기 편하게 잘 작성되어 있고, 스프링 공식 문서의 코틀린 챕터도 잘 정리되어 있다.
- 개인 기술 블로그 : 안드로이드 기술 블로그의 포스트를 읽으면 기초 문법을 학습하기 좋다.
- 코프링 프로젝트 : 소스코드 분석을 통해 도움이 된다.
코틀린과 코프링의 장점은 다음과 같이 분석했다.
- (코틀린) 자바 대비 상대적으로 간결한 문법
- (코틀린) 언어 레벨에서 다양한 기능 제공 (null safety, infix function, scope function, coroutine..)
- (코틀린) 지속적 업데이트와 활발한 커뮤니티
- (코틀린) IDE(IntelliJ) 레벨의 강력한 지원
- (코프링) 스프링 진영의 적극적 지원
- (코프링) 국내 많은 IT 대기업, 스타트업에서 도입해 사용하기 때문에 검증되어 있음
- (코프링) 증가하고 있는 레퍼런스 자료
신규 프로젝트에 투입되면서 모든 것을 새로 시작하면서 하고 싶던 것들이 있었다. 코프링을 먼저 제안했는데 예상 외로 긍정적인 반응이 있었다. 팀의 기반 기술 스택(JVM, 스프링 등)을 그대로 사용하면서 팀원들도 이미 여러 경로를 통해 코프링에 노출이 된 상태였기 때문이라 생각한다.
반면 WebFlux와 coroutine은 POC를 통해 도입하기로 했다. 이 부분들은 내가 웹과 스프링쪽 지식이 없어 이해가 어렵다.
어쨋든 결과적으로 WebFlux가 아닌 기존의 MVC로 진행하기로 했다. 이 과정을 통해 배운점은 비즈니스를 위한 기술이 우선이라는 점이다. 기술을 사용하기 위해 비즈니스를 억지로 맞추는 것은 안 된다.
코프링은 기본적으로 스프링이기 때문에 크게 문법과 같은 것들이 달라지지는 않는다. 빌드 부분만 플러그인 부분에서 다르다.
다음은 프로젝트에 도입해볼만한 유용한 플러그인과 라이브러리다.
- kotlin-logging : 자바 @Slf4j와 유사한 방식으로 사용 가능한 로깅 라이브러리
- refreshVersions : Gradle 프로젝트에서 사용(Gradle task)하는 의존성 버전 관리 플러그인
- ktlint-gradle : kotlin lint의 wrapper 플러그인
- Fixture Monkey : 테스트 객체를 편하게 자동 생성하는 라이브러리
코틀린을 도입할 때 고려할만한 내용은 다음과 같다.
- IntelliJ에서 코드 분석 기능이 자바 대비 아쉬운 성능이다. (다만 최신 IntelliJ에서 많이 개선을 진행 중)
- 코드 스타일 가이드라인이 있지만 언어 레벨에서 굉장히 많은 문법을 지원하기 때문에, 코딩 컨벤션을 정할 부분이 많다.
- scope functions 오남용은 가독성 저하와 로직 변경 대응이 취약하다. 기능에 잡아먹히면 안 된다.
- nullable 체크의 "?" 문법은 Optional로 Wrapping 타입이 필요할지 논의가 필요하다. 관용적으로는 ?를 사용하는 것을 권장하나, 무엇이든 일관성 있게 사용하는 것이 좋다.
주니어 개발자로서 팀에 새로운 기술을 도입한 것에 대한 이야기를 한다. 주니어는 여러 부분을 채워가며 신뢰를 쌓아가는 단계다. 기술 역량, 업무 도메인 지식, 커뮤니케이션 스킬, 책임감 모두를 쌓아가면서 이를 바탕으로 팀원을 설득해야 한다.
주니어가 시니어들을 설득하는 것은 매우 힘들다. 미리 공부하고 준비하는건 필수적이다. 공부할 때는 여러 소스 코드와 그 분야에 능숙한 개발자와 이야기하는 것도 도움이 많이 된다. 도입할 기능을 바탕으로 현업의 내용을 간단하게 구현해보는 것도 설득에 도움이 된다. 팀에서 자주 언급하고 좋은 레퍼런스를 공유하는 것도 설득에 도움이 된다.
구글 Apps Script와 ChatGPT로 많은 동료들 생산성 향상 시킨 썰 - 송요창
ChatGPT를 업무에 적용해 생산성을 향상시킨다는 사람들이 늘고 있다. 그런데 개인적으로는 어떻게 적용하는지 궁금했다. 간단한 코드를 대신 짜달라는 정도는 직접 짜는거나 큰 차이가 없을것 같다고 생각한다. 그런데 우아한 형제들에서 이러한 경험을 했다는 점이 궁금해 세션을 보게 되었다.
굉장히 귀찮지만 중요한 일에 적용할 수 있다는 사실을 알았다. 실제품에 적용하는 것이 아니고, 특히 개발자가 직접 다루는 일이 아니라면 더욱 필요할 수 있겠다 생각이 들었다. 다만 ChatGPT가 바로 훌륭한 코드를 가져오지는 않기 때문에 어느정도 요청한 코드에 대한 지식이 필요하기는 하다고 생각이 든다.
이 세션의 내용은 ChatGPT로 생산성 향상을 시킨건 맞지만 자신의 생산성을 향상시킨 것이 큰 것 같지는 않다. 자신의 생산성은 구글링을 통해서 구현한 것과 크게 다르지는 않은 것 같은 수준이다. 여기서 말한 생산성 향상은 비개발자분들의 귀찮고 중요한 일을 자동화 시킨 부분이다. 이 기능을 만들 때 ChatGPT를 사용한 것이다.
지속 가능한 소프트웨어 개발을 위한 경험과 통찰 - 백명석
세션은 규육에 대해 먼저 말을 하고 시작한다. 이번 세션 자체가 규율에 대해 얘기하는 것이 많기 때문이며, 시작할때 미리 규율에 대한 거부감이 있으면 받아들이기 힘들 수 있다고 경고한다. 과하게 규율에 대해 얘기하더라도 규율의 본질적인 부분에 좀 더 집중해서 들어주길 부탁한다.
먼저, 규율(Discipline)은 다음과 같이 구분이 가능하다.
- 본질적 부분(Essential)
- 규율의 존재 이유
- 규율에 권위 부여
- 임의적 부분(Arbitrary)
- 규율에 형태/실체 부여
- 임의적 부분이 없이는 규율의 존재가 불가능
예를 들어, 외과 의사가 수술에 들어가기 전에 손을 청결히 해야하는 부분은 규율의 본질적인 부분이다. 그러나, 손의 어떤 면을 몇번씩 닦는 행위 자체를 정하는 것은 규율의 임의적 부분이다.
지속 가능한 소프트웨어는 두 가지 측면으로 구분할 수 있다.
- 변화하는 요구사항을 지속적으로 수용 가능한가
- SW는 제조업과 달리 서비스 오픈 이후의 비용이 80%를 차지한다. 따라서, 제조업의 경우 품질이 높으면 비용이 올라가는 직관적인 관계를 갖는데, SW의 경우에는 품질이 높으면 향후 비용이 낮아지는 비직관적인 관계를 갖는다.
- 변화하는 환경에 맞는 개발 방법을 적용할 수 있는가
- 예전에는 잘 설계된 사전 설계(지도)를 바탕으로 터미널(vi) 개발을 했으나, 최근에는 인터넷을 통해 IDE(네비게이션)을 바탕으로 개발 환경이 변경되었다. 최근에도 TDD 방식 자체가 Inside-out에서 Outside-in으로 환경이 바뀌었고, 모의 객체를 사용하는 방식, 수직 슬라이스를 사용하는 방식 등이 변화하고 있다.
그리고 FAQ로 먼저 자주 물어보는 내용들에 대해 답변을 먼저 해주도록 세션이 구성되어 있다. 아마 경력이 많으신만큼 평소에 자주 듣던 질문들에 대해 간단히 정리해서 답변을 해주시는 것 같다.
TDD, 리팩터링이 좋은 줄은 알겠는데 현재 회사에서는 적용할 환경이 아닌거 같다는 질문도 많이 받는다고 한다. 관리자가 허용하지 않을 것이라 하는데 실제로 문제가 있는 조직도 일부 있겠지만 우리가 결정해야할 전문적인 일에 허락이 필요한가라는 의문이 먼저 든다고 한다. 일정과 기능의 요구사항은 조직에서 결정할 수 있겠지만 개발하는 방법 자체는 실제로 일하는 사람이 정해야 하지 않을까 싶다.
어려운 기술을 배우는 방법은 쉬운 문제에 적용해보는 것이다. TDD로 유명한 켄트 벡이 직접 답하기도 한 것인데 TDD를 연습하기 위해서는 한 번 풀어본 문제에 TDD를 적용해보는 것이 익히기 좋다고 한다. 즉, 쉬운 문제에 어려운 기술을 적용시켜 보는 것이다. 반대로 회사에서 어려운 문제를 풀어야 할 때는 쉬운 기술을 적용해야 한다.
켄트 벡 뿐만 아니라 다른 유명한 개발자들이 많이 강조하던 내용들을 똑같이 강조한다. 가독성이 중요하고 TDD와 리펙터링이 중요하고 과도한 설계를 피하자는 등의 내용들을 설명한다.
지금 읽고 있는 "프로젝트에서 제품으로"라는 책에서 소개하는 내용도 설명한다. 일에 사람을 할당할 것인가 사람에 일을 할당할 것인가에 대한 내용으로 가치흐름을 설명할 때 나오는 내용이다. 일에 사람을 할당할 경우 n명의 사람에게 n개의 일을 각각 할당하는 것이다. 일에 사람을 할당하면 사람마다 일에 대한 공유가 없고 병목이 발생할 수 있다. 그러다보면 왜 같은 팀인지도 모르게 된다. 하지만 사람에 일을 할당하게 되면 n명에게 큰 하나의 일을 할당하는 것으로, n명이 n개의 일을 한 번에 하나씩 같이 처리하는 방식이다. 사람에 일을 할당하는 것은 지식이 공유되며 대기가 없어지고 팀워크와 몰입이 생기게 된다.
출시 3일만에 앱스토어 2위를 달성한 사이드 프로젝트 - Skrr(김현준, 김아인)
유튜브에서 인터뷰 영상을 이미 봤어서 알고 있던 앱이었다. 그 전에는 미성년자와는 시기가 멀어 알지 못했던 앱인데 고등학생들끼리 이런 사이드 프로젝트를 수행했다는게 대단하다 생각했다. 앞으로 Skrr 말고도 좋은 주제들로 개발을 해서 다른 주제로도 발표하는걸 보고싶다. 개발자분들이 스타트업을 들어갈지 대기업 같은 곳을 들어갈지 잘 모르겠지만 앞으로도 좋은 주제들의 다른 발표도 보고싶은 마음이 있다. 내가 스타트업을 도전해보지 못했고 이제는 더 걱정만 쌓여 그런 것 같다.
직장에 가서 개발할때 고려해야할 부분들을 미리 직접 경험해본 것만으로도 부러운 경험이다.
2곳 중 1곳은 무조건 합격하는 개발자 이력서 만들기 - 지소라
비개발직군에서 일을 하다가 개발로 점차 업무가 넘어가다가 부트캠프를 거쳐 백엔드 신입으로 들어가게 되었던 분이 발표를 해주신다.
개발자 이력서 뿐만 아니라 이력서 자체에 대해서 알아야 한다. 이력서는 가장 dry한 문서다. 즉, 이력서는 가장 전문적인 문서다. 이력서에 쓰는 한 문장은 쓸모없는 내용이 없어야 한다. Why, How, What 중 최소 2가지는 포함되어 작성되어야 한다.
내용이 너무 길면 너무 풀어쓴 것이고, 내용이 짧다면 핵심을 잡지 못한 것이라 볼 수 있다. 해왔던 일이 무엇을 위해 어떻게 했는지에 대한 핵심을 뽑아내면 한 문장을 적기 쉬울 것이다.
이력서는 길게 만들면 안 된다. 컴팩트하게 만드는 것도 능력이다. 이력서를 만들 때 같은 내용이더라도 구글 독스와 노션이라는 플랫폼의 차이도 존재하니 고민해봐야 한다.
이력서를 다 읽었을 때 결과적으로 무슨 일을 할 줄 아는지가 와닿아야 한다. 어떤 것들을 해봤는 지에만 집중할 것이 아니라, 어떤 것을 했을 때 어떤 결과로 이어졌는지가 중요하다. '이렇게 해본 것들이 많아요~'라고 작성하는게 아니라 '이렇게[ 해본 것으로 이런것까지 만들어 봤어요~'가 되어야 한다.
이력서에 작성되는 내용은 기획 의도를 작성하는 것이 아니다. 어떤 문제가 있었고, 어떤식으로 구체화했고, 기술적으로 어떻게 해결했는지가 필요하다. 이를 통해 자신을 어필해야 한다.
마지막으로 여태까지의 작업물을 모아볼 수 있는 모음집이 있어야 한다. 모음집이 있어야 얼만큼의 고민을 갖고 기술적으로 풀어냈는지 알 수 없다. 포트폴리오에는 문제 해결의 스토리를 작성해야 한다.
우리가 고전 동화의 스토리를 한 번만 듣고 기억하는 이유는 스토리가 "불가피한 외적 문제로 주인공이 문제 해결을 위해 내적으로 변화하는 과정"이기 때문이다. 즉, 주인공인 우리가 어떤 외적 문제를 만나 무엇을 위해 어떻게 해결했는 스토리를 풀고, 경험을 통해 얼만큼 성장했는지도 어필하면 된다.
코드를 보여주는 것 보다도 무슨 문제를 어떻게 해결했는지가 더 매력적일 것이다.
업무를 진행하면서 작업한 내용들을 많이 지우기도 했고 관리를 하지 않았는데 빠른 시일내에 정리할 필요가 있다고 느꼈다. 특히 문제 상황과 결과는 알기 쉬워도 고민한 내용들은 잊은게 많을 것 같아서 아쉽다.
이력서는 퇴고가 매우 중요하다. 당일 쓴 글을 당일에 퇴고하는건 크게 도움이 되지 않는다. 그러니 최소 한 달 정도 꾸준히 퇴고해야 한다.
인프런 아키텍처 2023~2024 - 이동욱
아키텍처 변경은 보통 장애나 트래픽 문제로 인해 발생하게 된다. 하지만 인프런은 작년부터 아키텍처 변경 계획을 세운 이유가 조직의 구조에 변화가 생겼기 때문이다. 아키텍처를 변경하면서도 많은 문제들이 발생했다.
백엔드 8명, 데브옵스 4명, 프론트엔드 12명의 소규모 인프런 개발조직에서 아키텍처를 개선하기 위한 준비 작업에 어떤 것들이 있었는지 소개한다.
작년에 소개한 아키텍처에서는 거대한 레거시 시스템이 있었고 개선하기 위한 신규 프론트엔드와 백엔드 스택을 하나씩 위치시켰다. 레거시에 있던 기능들을 하나씩 프론트엔드와 백엔드로 이동시키면서 레거시는 줄이는 계획을 설명했다. 그러나 지금도 여전히 비슷한 모습이다.
변화하지 못한 이유로, 회사의 규모가 커지면서도 비즈니스 속도를 유지하기 위해 조직의 형태에 변화가 있었다. 규모가 적었기 때문에 빠르게 반응하고 대응할 수 있었지만 규모가 커지면서는 문제가 있을 수 있다. 이를 방지하기 위해 먼저 조직형태를 바꾸기로 한 것이다.
기존에는 PM팀, Design팀, 개발팀과 같이 기능조직으로 이루어져 있었다. 그러다보니 조직별로 목표가 달랐다. 게다가 아주 작은 기능의 변화가 일어나도 3개의 팀이 함께 협업이 필요했다.
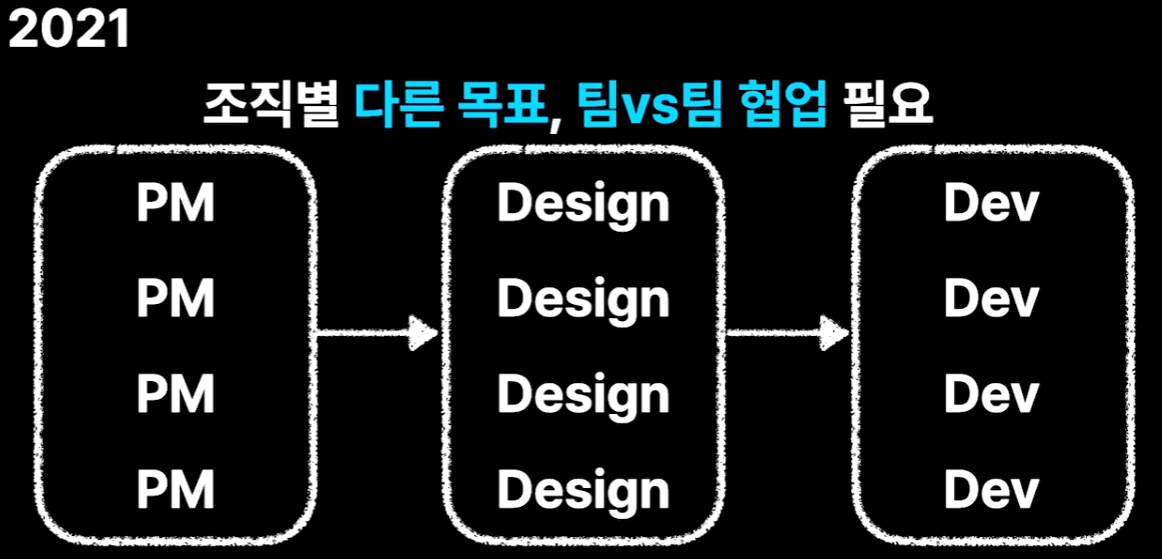
최초의 스타트업 형태에서는 규모가 작기 때문에 그 자체로 모두가 한 팀이었다. 같은 목표를 공유했고 여러 팀이 협업을 위해 일정 조정 등을 따질 필요가 없었다. 그래서 현재는 예전의 형태로 되돌아가기 위해 다음과 같이 Cell이라는 조직 단위를 두었다. 하나의 목표마다 Cell을 하나씩 만들게 되었다. 스포티파이의 스쿼드 팀 구조가 가장 유명한 형태다.
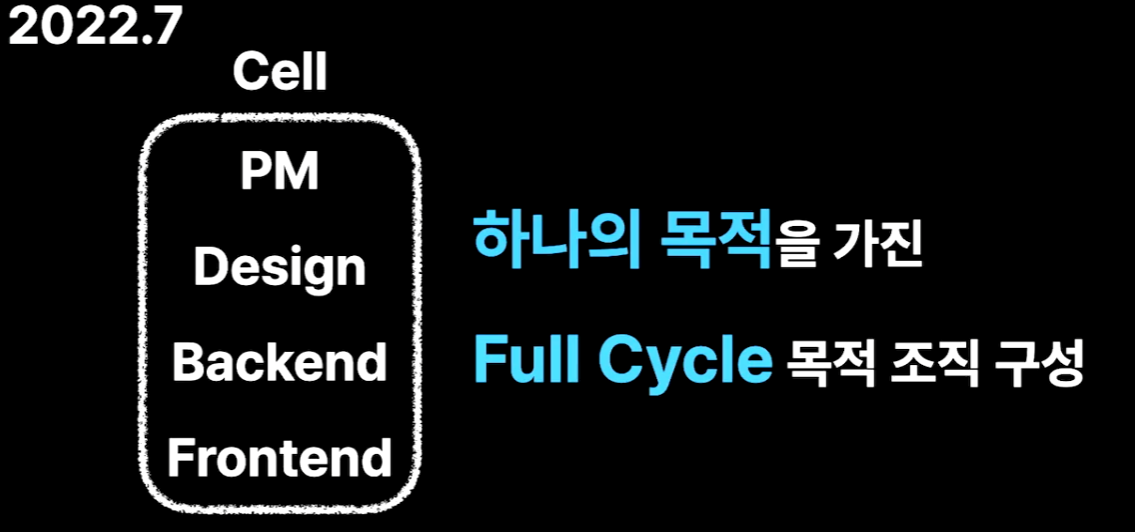
조직의 형태를 변경하고 하나의 제품 단위 안에서는 빠르게 의사 결정이 이뤄졌다. 그결과 인프런 안에서 예전 초기와 같이 매달 2~3개 이상의 제품 개선 및 출시가 이뤄졌다.
스쿼드 팀 구조의 장점으로는 앞서 말했듯이 실행력이 생기며과 속도감이 올라가게 된다. 하지만 단점으로는 장기적인 제품의 속도는 저하될 수 있고 조직의 안정감도 낮아지게 된다. 단위 조직의 제품에 대한 지표 개선이 최우선이 되기 때문에 실질적인 내부 코드의 개선은 게을러지게 되는 것이다. 또 다른 문제로는 시니어 개발자의 부족으로 각 Cell마다 모두 시니어 개발자를 배정할 수 없었다. 마찬가지 이유로 작은 단위의 조직에서 1명씩 존재하는 직군에 퇴사자가 발생할 경우 조직이 동작하기 어렵다.
인프런에서는 결과적으로 단기적인 속도감을 높인 상태로 유지하면서 장기적인 속도와 조직 안정감도 향상시키기로 목표를 설정했다.
스쿼드 팀 모델에서는 보통 스쿼드 팀 자체만 있는 것이 아니라 챕터라는 모델이 같이 존재한다. 목적 조직이 스쿼드(Cell), 직군 조직이 챕터(Part)인셈이다. 이 파트가 서브 조직이 되는 형태로 구성했다.
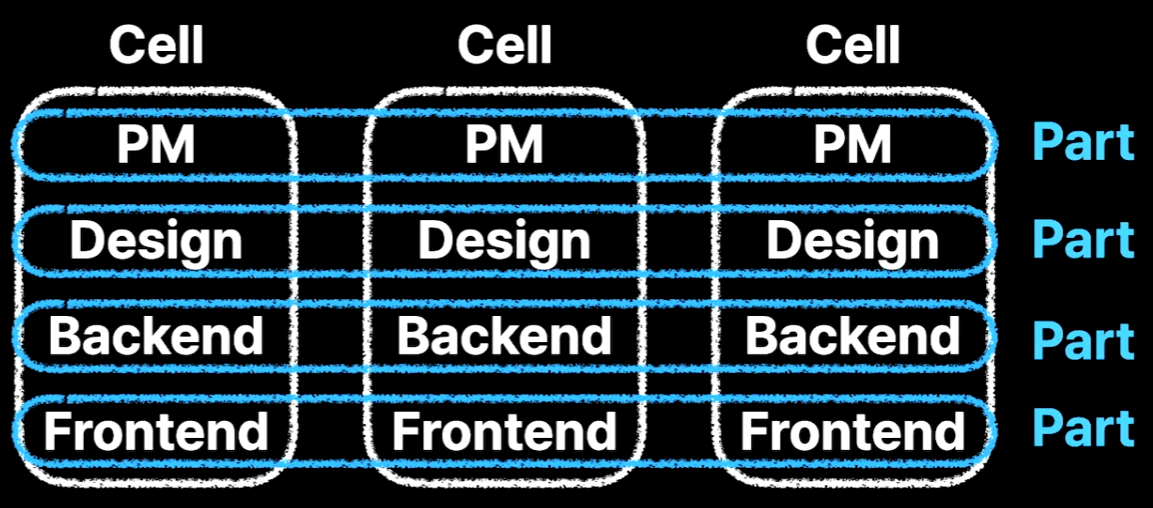
보통 서브 조직에서도 지식 공유가 활발하게 이뤄질 수 있기 때문에 파트별 위키를 신설했다. 또한, 파트별로 정기 미팅을 함으로써 기술 공유가 더욱 활발하게 이뤄질 수 있도록 도왔다. 스쿼드 단위 업무의 풀리퀘스트(PR)은 모두 각 파트의 공용 채널에 공유하기로 했다. 비즈니스 로직까지는 알지 못하더라도 코드상 오류나 컨벤션의 경우에는 공유될 수 있다.
이제는 조직 개편 이후 실제로 아키텍처를 어떻게 변경할 것인지를 고민해야 한다. 여전히 1개의 레거시 프로젝트가 존재하고 있는데 목적 조직은 이미 N개로 분리된 상태다. 그러다보니 자연스럽게 빌드 속도는 점차 늘어나고 커밋 로그는 뒤섞이고 QA 작업의 일정에도 서로 영향이 갔다. 앞서 말했듯이 장기적인 속도가 느려졌다. 이제 거대한 단일 레거시 시스템의 개편은 회색 지대가 되었다.
이 문제의 해결방법으로는 보통 MSA를 생각한다. 하지만 소규모 팀이 MSA 구조로는 비즈니스 속도를 낼 수 없다. 하나의 조직이 담당하는 서비스는 많아야 두 개여야 한다. 따라서 소규모 조직으로는 MSA를 유지하기 힘들다.
결과적으로 선택한 해결방법은 레거시 프로젝트를 각 팀마다 복제해 담당하는 부분만 나눠 갖도록 해 조직별로 레거시 시스템을 갖도록 했다. 이렇게 하면 작은 조직은 작은 레거시와 작은 신규 프론트엔드와 백엔드를 나눠 갖는 형태가 된다. 즉, 이제는 회색 지대가 없이 모두 업무를 나눠 가졌다. 앞선 단점들도 사라졌고, 무엇보다 이제는 레거시 개편이 각 목적 조직의 실제 목표가 될 수 있었다.
이렇게 조직별로 레거시를 나눴을때 대해 문제가 있었다. 1개의 서비스가 N개의 프로젝트로 나뉜 것이기 때문에 인프라를 N배로 증설해야하는 문제가 있었다. 이에 인프런에서는 IaC(Infrastructure as Code)에 집중하기로 했다. IaC는 코드를 작서하면 인프라를 자동으로 구축해주는 것을 말한다. pulumi라는 기술로 인프라를 전환해 현재 서비스 인프라를 쉽게 복제할 수 있도록 만들었다.
이 뒤로는 인프라 변경을 하면서 적용한 AWS 구성에 대해 설명한다.
가장 인상깊은건 조직을 나누면서 API 콜이 많아졌는데 앞단의 하나의 API를 호출했을 뿐인데 뒷단의 API 처리를 어떻게 수행할지, 사용자는 모든 API 콜을 마칠 때까지 대기시킬 지 등에 대해 고민을 했다고 한다. 이때 SNS-SQS 비동기 아키텍처를 적용해 문제 해결을 했다고 했다. Kafka까지는 필요가 없어 간단한 비동기 메시지 큐를 이용했다고 보면 된다. 비동기 적용은 트랜잭션이 필요한 곳에서는 절대 사용해서는 안 된다.
생각보다 개인적으로는 인프라 전체적인 구조보다는 조직 구조와 관련해서 더 흥미가 있었다. 인프라 구조는 AWS의 각 서비스를 잘 몰라서 그런지 대강 이해만 하고 넘어갔다.
오늘도 여러분의 API는 안녕하신가요?: API First Design과 CodeGen 활용하기 - 김정규
API로 고통받았던 경험은 많은 이들이 겪는다. 가장 흔한건 API 문서와 실제 동작에 차이가 있을 때다. 프론트엔드 개발자는 백엔드 개발자에게 API 문서를 받지 못하거나 문서와 다른 동작을 해서 당혹스러웠을 것이다. 백엔드 개발자는 API 설계를 위해 빈페이지를 처음 마주하는 순간 머리가 하얘질 것이다. 그것뿐만 아니라 API 명세가 바뀌었을때 문서도 업데이트가 되지 않아, 더이상 사용되지 않는 API가 방치되고 있어, 문제였던 경험들이 있을 것이다.
발표자가 겪었던 기존 API의 문제들 중 첫 번째는 일관성이 없는 API 설계 문서로 인해 일관성 있게 관리하기 위한 관리 비용이 증가한 것이다. 처음 백엔드 개발자가 작성한 API 설계문서는 만드는 사람마다 wiki, 엑셀 등 다양한 템플릿과 작성 기준이 상이하다.
두 번째는 두 단계로 구성된 번거로운 API 문서 작성이다. 초안의 API 설계 문서 작성과 최종 프론트엔드로 전달되는 API 문서 두 개를 만들어야 한다. 특히 초안의 API 문서를 남겨 추후 유지보수시 혼란이 생길 수 있다.
세 번째로 코드 변경사항이 최종 API 문서에 반영되지 않는 것이다. 비즈니스 요구사항의 변화로 코드 변경이 발생하면 API 문서도 업데이트가 되어야 한다. 그러나 문서화 도구를 스킵하고 프론트엔드에 구두나 텍스트로 직접 전달하는 경우가 발생해 문서는 업데이트되지 않는 문제가 있다. 이 문제는 API 변경사항을 API 명세보다 코드 구현 작업에 집중했기 때문에 발생한 것이다.
네 번째로 서로 다른 API Path지만 결과적으로 같은 기능이 있는 문제다. 하나의 서비스를 장시간 운영하다보면 발생할 수 있는 문제다. 이 또한 API 변경을 명세보다 코드 구현에 중점을 두다보면 발생할 수 있는 문제다. 이렇게되면 이해관계자들간 어떤 것이 변경이 되어야 할지에 대해 불필요한 의사소통이 증가하게 되는 원인이 된다.
다섯 번째로 같은 기능이지만 다른 용어를 사용하는 문제다. 이역시 마찬가지로 API 변경사항을 명세보다 코드 구현 작업에 중점을 두었기 때문에 발생한 문제다. 백엔드 개발자와 프론트엔드 개발자간 의사소통 시에는 같은 용어지만 실제 코드에서는 서로 다른 용어를 쓰게되면 의사소통에 문제가 생겼다.
이런 문제들을 겪고 개발자들이 부주의했다고만 생각했다. 발표자는 API가 부수적인 것이고 단순히 데이터를 전달하기위한 수단으로만 생각했었다. 하지만 위의 문제들을 겪으면서 자세가 바뀌었다고 하며 위의 문제들을 해결하기 위해 API First Design을 생각했다.
API를 이해 관계자들간 합의해 정의한 계약서라 생각하자. API 계약서를 위배해서는 안 되는 것이다.
하나의 API가 유효하기 위해서는 필요한 기준이 명확히 있고 기준에 따라 API 계약서를 작성해야 한다. 여기서 기준은 OAS(Open API Specification, Open API 명세서)이라 한다. OAS는 "언어에 구애받지 않는 HTTP API 표준 인터페이스"다.
API First Design은 OAS 기반의 API 계약서를 우선순위 1순위로 고려해 협업 및 설계하는 것이다.
API First Design으로 문제를 해결하기 위해서는 API 계약서만으로도 앞선 문제를 일부 해결 가능하다. 하지만 API First Design의 개발 방법을 보고 실제로 문제를 해결하는 것을 살펴보자. API First Design의 개발 프로세스는 다음과 같다.
- OAS 설계
- 백엔드 개발자와 프론트엔드 개발자가 함께 요구사항을 분석해 OAS 및 OAS 기반의 API 계약서 작성
- 반복적 설계 (토론 + 공유)
- 백엔드 개발자, 프론트엔드 개발자와 이해관계자까지 함께 계약서를 다듬는 과정
- Open API 도구 활용 및 구현
- API 문서
- Code Generators
- 서버 + 클라이언트 코드
- Mock Server
- API Gateway
- API 문서 전달
기존 프로세스는 코드 개발에 맞춰 API 문서 작성에 들어가는 Code First 방식이었다. 하지만 위의 프로세스대로 수행하는 API First 방식은 API를 먼저 작성한다.
API 계약서를 작성할 때 필수 요소가 지정되어있기 때문에 다른 누군가가 관리를 하더라도 일관되게 관리 가능하다. 처음에 작성한 API 문서가 최종적으로 프론트엔드로 전달되기 때문에 하나의 문서만 존재하게 된다. 코드 변경사항은 항상 API 계약서를 수정해야하기 때문에 항상 코드 변경 내용이 문서에도 반영된다. API Path가 다르지만 결과적으로 같은 기능인 점과 같은 기능이지만 다른 용어를 사용하는 문제는 API 변경사항이 API 명세에 중점을 두고 반영되기 때문에 해결된다.
API First Design의 장점은 다음과 같다.
- API 변경에 대한 히스토리 관리 가능
- 공통 API 문서를 통해 협업 가능
- 이해관계자들과 함께 API를 작성
API First Design을 도입했을 때 오해했던 점이다.
- Swagger는 API 문서화 도구
- Swagger는 API 문서 자동화는 기능 중 일부일 뿐이다.
- annotation 기반으로 만든게 정말 Swagger에서 만든건가? Spring boot에서 만든 것일 수도 있다.
- OAS는 Swagger API Specification에서 시작한 것으로, Swagger에서 의도한 API 문서화는 annotation 기반이 아니라 OAS 기반의 API 문서다.
- API First Design은 API를 한번에 결정하는 것
- 한 번에 다 만들 필요가 없다. 잘못된 부분은 OAS를 반복해서 설계 및 구현하는 과정이 필요하다.
- Open API Tools 중 Codegen은 만들어진 템플릿만 사용 가능
커뮤니케이션 잘하는 개발자의 4가지 습관 - 송범근
이번 세션은 요구사항 커뮤니케이션에 대해 다룬다. 토스 내에서 설문조사를 했을 때 개발자의 역량 중 가장 중요한 것을 '다른 직군과 협업할 수 있는 커뮤니케이션 능력'이었다. 23명의 작은 풀에서 여러 보기 중에서 5개 항목을 선택하도록 했지만 커뮤니케이션 능력만이 100% 결과를 가졌다.
단순히 '커뮤니케이션을 잘 하는 개발자'가 아닌 좀 더 자세히 정의해볼 수 없을까? 어떤 사람이 커뮤니케이션을 잘하는 개발자인지 발품팔아 물어보고 있었다. 그러면서 자연스럽게 커뮤니케이션이 안 되는 개발자가 어떤 유형인지 알 수 있었다. 발표자의 동료들이 느끼기에 커뮤니케이션이 안 되는 개발자는 '그냥 안된다'고 말한다.
이런류의 개발자를 스펙 구현형 개발자라 해보자. 요구사항을 명확히 엔지니어 측에서 전달해주면 스펙에 대해서만 잘 개발하는 개발자를 말한 것이다. 구현에만 집중하면 일에 대한 시야가 좁아진다. 따라서, 커뮤니케이션이 안 되는 개발자가 '그냥 안된다'고 말하는 이유는 스펙을 구현하는데 집중하기 때문이다.
반대로 커뮤니케이션을 잘하는 개발자는 문제 해결형 개발자라 해보자. 이런 개발자는 단순히 '안 된다'라는 말을 하지 않지만 그렇다고 무조건 '예스맨'도 아니다. 요구사항의 실제 목적을 파악하고 요청한 내용대로는 개발이 불가능하면 다른 방안을 제시하는 사람이다. '안 되는 사항'에 집중하는 것이 아니라 의도와 맥락을 이해해 고객과 사업의 문제를 풀기 위해 더 좋은 스펙을 만들어내고자 고민한다.
실제로 말을 잘한다거나 외향적이라는 것보다는 문제 해결 방식이 주요하다. 커뮤니케이션을 잘하는 개발자가 '안 된다'고 말하지 않는 이유는 문제 해결에 집중하기 때문이다.
누구나 주니어 단계에서는 스펙 구현형 개발자에서 시작할 수 밖에 없다고 본다. 점차 연차가 쌓이고 시야가 넓어진다면 문제 해결형 개발자로 변화하도록 노력해야 한다. 물론 쉽게 고쳐지는 영역은 아니다. 지속 가능한 행동하는 습관화가 필요하다. 좋은 습관 4가지는 다음과 같다.
- 요구사항을 들으면 '안 된다'는 말을 하기 전에 해결하려는 문제와 의도에 대해 묻는다.
- 상대방의 말을 듣고 이해한 바를 공유해 피드백을 받는다.
- 안 된다고 말할 때는 상대방 관점에서 대안을 제시한다. (기술적으로 어려운 안 되는 이유를 알고 싶은게 아니라 실제 어떻게 대처를 하면 좋을지 알고 싶을 것이기 때문에 제약을 덜 받는 다른 방향을 제시)
- 문제를 해결할 또다른 방법은 없을지 고민한다. (혼자 해결하지 말고 다른 사람들의 인풋을 받는 방법도 존재)
변별력을 200% 더 높인 개발자 채용 방법: 코드 리뷰 테스트 - 전종욱
"좋음에서 위대함으로 가는 전환에서 가장 중요한 자원은 사람이 아니다. 적절한 사람이다."
- <좋은 기업을 넘어 위대한 기업으로>
회사가 커짐에 따라 지원자 수가 늘어났고 그에따라 인터뷰 시간도 늘어나게 되었다. 하나의 인터뷰에도 시간과 노력이 많이 필요하기 때문에 실무 시간이 점차 줄어들 수 밖에 없었다.
기업의 코딩테스트는 지원자의 코딩 능력, 자료구조 지식, 문제 해결력을 확인할 수 있는 수단이다. 하지만, 코딩테스트만으로는 회사에서 필요한 역량을 모두 확인할 수 없다. 코딩테스트 점수만 높다고 채용을 할 수는 없는 것이다. 이를 보완하기 위해 인터뷰 시간을 할애해 지원자의 역량을 확인하게 된다.
코딩테스트의 허점이 하나 더 늘어난 것이 ChatGPT와 같은 것을 이용한 어뷰징 케이스다. 많은 기업에서는 단순히 코딩테스트가 아닌 과제를 풀게함으로써 어뷰징 케이스를 회피하면서 실무에 가까운 능력을 종합적으로 검토할 수 있다. 즉, 과제는 코딩테스트보다 검증 가능한 역량의 범위가 넓다. 하지만, 지원자 입장에서는 코딩테스트보다 과제 제출에 대한 부담이 더 크다.
그럼 지원자의 부담도 적으면서 지원자의 역량을 넓은 범위에서 검증할 수 있는 방법이 있을까?
좋은 코드 리뷰 문화를 회사에 정착시키도록 노력하면서 내 동료가 좋은 코드 리뷰를 해줄 수 있는 사람이면 좋겠다고 생각했다. 그래서 코드 리뷰 자체를 회사의 채용 프로세스로 적용하는 것으로 결정했다.
"코드 리뷰 테스트"는 코딩테스트나 과제처럼 지원자가 코드를 작성해 제출하는 방식이 아니다. 회사에서 제공한 코드에 대해 지원자가 코드 리뷰 내용을 제출하는 방식이다.
이를 회사에 적용하기 위해서는 코드 리뷰 테스트를 위한 문제를 만들어야 한다. 코딩테스트와 과제의 경우 인터넷에 적절한 문제를 선택하면 된다. 코드 리뷰 테스트를 위해서는 팀에서 좋았던 코드 리뷰 내용을 수집해 채용 문제로 제출해도 괜찮을지 검토를 진행했다.
적합한 코드 리뷰의 문제일지 선택하는 데 "팀내 개발자 기술 인재상"을 먼저 정의한 것을 반영했다. 이후, 실제 운영 환경의 코드는 너무 크기 때문에 작은 사이즈의 프로젝트로 축소시켰다. 사내 자체 검증을 통해 1시간 이내에 완료할 수 있을 정도의 크기로 반복해서 경량화를 진행했다.
실제 코드 리뷰 테스트 도입의 결과로 지원자 수와 합격자 수에는 큰 차이가 없었다. 하지만 중요한 부분은 코딩테스트를 합격한 사람의 인터뷰 합격률(25%)보다 코드 리뷰 테스트의 합격한 사람의 인터뷰 합격률(53%)이 2배 이상 높았다. 이로써 코드 리뷰 테스트를 통해 보다 팀에 적합한 사람을 골라낼 수 있었음을 말하고, 인터뷰 시간은 훨씬 감소했음을 말한다.
물론, 코드 리뷰 테스트 문제의 난이도를 매우 높게 설정했다면 코드 리뷰 테스트의 합격자는 인터뷰를 무조건 합격할 수준일 것이다. 이러한 방식이 옳다고는 볼 수 없다. 이를 위해 건전성 지표를 확인해야 한다. 건전성 지표는 기존 대비 떨어져서는 안되는 수치를 말한다.
첫 번째 건전성 지표는 최초 응시자의 실제 직무 인터뷰 통과 비율로 설정했다. 즉, 코딩테스트를 사용했을 때 응시자의 최종 합격률보다 코드 리뷰 테스트를 사용했을 때 응시자의 최종 합격률이 더 낮아지면 안 된다. 실제 건전성지표 결과는 코딩테스트의 최종 합격률(15%) 보다 코드 리뷰 테스트의 최종 합격률(20%)이 더 높았다.
두 번재 건전성 지표는 테스트 제출률로 설정했다. 테스트가 너무 어려워 제출하는 사람이 거의 없다면 큰 의미가 없다. 지원자의 부담이 비슷해야 한다. 실제 건전성 지표를 확인해보면 코딩테스트의 제출률(84%) 보다 코드 리뷰 테스트의 제출률(85%)이 더 높았다.
코드 리뷰 테스트를 운영하면서 느꼈던 장점들은 다음과 같다.
- 실무 능력 파악 가능
- 문제 인식 능력 파악 가능
- 검증 항목 유연하게 설정 가능
- 협업 및 커뮤니케이션 능력 확인 가능
- 지원자의 심리적, 시간적 부담이 적음
- 지원자의 다양한 기술적 관점 확인 가능
- 인터뷰 횟수 감소
- 전체적인 채용 리드 타임 감소
- 채용 리드 타임 : 지원자의 최초 지원부터 최종 합격까지의 시간
- 인터뷰에 활용 가능한 구체적 자료 확보 가능
- 코드 리뷰 내용을 바탕으로 인터뷰에서 풍부한 질의 가능
- ChatGPT 어뷰징 회피 가능
- 100% 확신할 수는 없지만 코딩테스트 보다는 안전하다고 느
물론 한계도 충분히 있었다.
- 신입 대상으로는 적용 불가능
- 기술 스택과 코드 리뷰에 익숙한 사람에게 적용 가능
- 기술 스택이 다른 지원자는 불리
- 채용 과정에서 형평성을 챙겨줘야하지는 않지만 다른 기술 스택의 훌륭한 사람을 놓칠 가능성
- 특정 기술에 종속되지 않은 일반적인 주제도 포함시킴으로써 해결 시도 (예를들어 자바-스프링 사용하는 팀에서 스프링을 사용하지 않아도 리뷰가 가능할 문제가 필요)
안타깝게도 오늘의 TDD는 실패한 것 같군요. 내일은 가능할지도...? - 한윤석
"문제"란 내가 바라는 것과 인식한 것의 차이라고 볼 수 있다. 아이패드를 갖고 싶은 것은 바라는 것이고, 아이패드가 없다는 상황이 인식한 것이다. 이 둘 사이의 차이가 "문제"다. "문제 해결"은 바라는 것과 인식한 것에 대한 차이를 줄여 일치시키는 것이다.
문제를 잘 해결하려면 다양한 문제를 많이 풀어보는 수 밖에 없다. 이전에 비슷한 문제를 풀어봤다면 문제 해결에 유리하기 때문이다. 당연히 무조건 많이 푼다고 무조건 좋은 것은 아니다. 체계적으로 풀지 않으면 이전에 적용한 해결 방법을 새로운 문제에 적용할 수 없다.
체계적으로 문제를 파악하기 위한 방법으로는 "거꾸로 연구하기" 방법이 있다. 거꾸로 연구하기란 요구하고 있는 것부터 시작해 나의 현재 상황까지 거꾸로 문제를 해결하는 것을 말한다. 이미 내가 원하는 것을 찾았다고 가정하고 가정이 되기 위해 어떠한 과정이 필요할지 고민하는 것이다.
이 과정이 TDD 방식과 동일하다.
- 실패하는 테스트를 작성한다. (요구사항을 작성한다.)
- 테스트를 통과시킨다. (요구사항을 해결한 것처럼 가정한다.)
- 리팩터링한다. (원하는 결과를 어떤 전제로부터 이끌어낼 수 있을지 질문한다.)
예제들을 간단히 보여주면서 진행하는 설명과 간단한 코드 정도는 이해할 수 있다. 하지만 js를 모르기 때문에 자세한 문법은 잘 모르겠다. 아무튼 다른 TDD 기본을 설명하는 책처럼 간단한 예제로 TDD를 보여준다.
왜 내가 만든 서비스는 아무도 안 쓰지?: 개발자가 알아두면 좋은 사이드 프로젝트 제작 팁 - 이동훈
발표자는 비전공자 출신의 군대 때 독학으로 개발을 공부했다. 사이드 프로젝트만 29개를 진행하면서 개발을 최대한 많이 하려고 노력했고 그중 가장 유명한 사이드 프로젝트는 하루만에 완성했던 코로나맵이다.
사이드 프로젝트들을 진행하다보니 공통적으로 성공하기 위해 필요한 것이 보이기 시작했다. 실제 코딩하는 개발 분야 보다는 개발 외적인 부분(기획, 디자인, 배포, 운영 등)이 많이 보이기 시작했다. 개발 방법에 대한 내용은 워낙 좋은 강의들이 많아 생략하며, 사이드 프로젝트를 진행해보면서 경험했던 개발 외적인 내용들을 공유한다.
1. 좋은 문제를 찾고, 이해하고, 해결하자
작품과 상품의 차이를 살펴보자. 작품은 작가의 생각으로 만들어지는, 나로부터 시작되는 것이다. 반대로 상품은 시장의 니즈로 만들어지는, 사용자로부터 시작되는 것이다.
주니어 개발자는 보통 상품을 생각하지 못하고 작품을 생각하고 사이드 프로젝트를 진행한다. 즉, 솔루션을 먼저 정의하고 사용자를 솔루션에 끼워맞추는 실수를 하고 있다. (기술을 강조하고 특정 솔루션을 강조하려는 목적이 있는 사이드 프로젝트가 아니라면) 기술 스택이나 해결 방법이 우선이 아니다.
상품을 만들기 위해서는 좋은 문제를 찾아야 한다. 좋은 문제를 찾기 위해서 다음 3단계의 프로세스를 구축했다.
- 반문하기 : 주변에 당연한 것들, 당연한 프로세스들에 대해 반문하기
- 관찰하기 : 기존의 프로세스들이 어땠는지 관찰하기
- 펼쳐보기 : 왜 이런 현상이 발생했고, 어떤 부분을 해결할 수 있고, 시장의 크기는 어느만큼 클지
주변의 문제를 찾는 것이 처음 사이드 프로젝트를 진행할 때 어려움을 겪는 부분이다. 주위에서 문제를 찾기 어렵다면 나 자신이 고객인 문제를 찾아보면 된다. 내가 고객인데 불편한 것이 있지는 않은지 찾아보자.
2. 가능한 짧은 시간 내에 완성하기
사이드 프로젝트를 지속하게 만드는 것은 동기부여다. 처음 시작하는 사이드 프로젝트는 돈이 목적이 아닌 개인의 성장과 즐거움이 목적이자 원동력이다. 사이드 프로젝트의 특성상 완성되지 않으면 그간 쏟아 부은 시간이 그대로 허비되는 경우가 많다.
하지만 늘 이를 방해하는 요인이 있다. 크게 다음 2 가지로 볼 수 있다.
- 점점 늘어나는 기능
- 처음부터 완벽하게 개발하려는 생각
짧은 시간을 제한으로 두고 나머지를 맞춰야 한다. 출시 이후 고객의 피드백을 받아 개선해도 충분하다. 프로젝트 규모에 따라 최대 기간을 3개월에서 6개월로 선정해야 한다. 그 이상이 넘어갈 경우 사이드 프로젝트의 프로세스가 잘못된 것이다.
오래 개발한다고 완성도 있는 서비스가 나오는 것도 아니다. 핵심 기능 하나에 집중하도록 하자.
3. 만든 여정 기록하기
대부분의 사이드 프로젝트는 실패한다. 사이드 프로젝트는 끝나면 남는게 없다. 실력적인 성장이나 경험은 쌓을 수 있지만 결과물이 남아있지 않다면 다른 사람들은 내 경험을 알지 못한다.
기록을 남겨야 하는 것들은 다음과 같은 것들이 있을 수 있다.
- 어떤 문제를 어떻게 해결했는지
- 어떤 기술 스택을 왜 사용했는지
- 어떤 결과가 있었고 무엇을 얻었는지
단순히 문제, 기술 스택, 결과만 기록하는 것이 아닌 이유와 팔로우업이 필요하다.
작은 시도, 작은 실패, 작은 성공을 통해 부담을 갖지 말고 시작해 실력과 경험을 쌓아나가도록 해보자.
왜 구글 시니어 개발자는 코딩을 안할까? - 이다니엘
구글은 시니어 개발자들, 점점 높아질수록 코딩을 별로 하지 않는다. 개발할 때 어떤 언어를 많이 쓰냐는 질문에 "영어"라고 답변을 주고, 어떤 IDE를 쓰냐는 질문에 "Google Docs"로 답준다. 실제로 스태프 개발자 이상은 회의나 팀원간 대화, document 작성 등을 위주의 업무를 한다.
개발자는 영어로 뭐라고 할까? programmer? software developer? software engineer?
외국 채용 공고를 살펴보면 "Software Engineer"라는 용어를 많이 쓴다.
그렇다면 소프트웨어 엔지니어링은 뭘까?
소프트웨어 엔지니어링은 프로그래밍에 시간과 다른 프로그래머들을 더할 때 발생하는 현상이다.
Software engineering is that happens to programming when you add time and other programmers.
- Russ Cox

연차가 낮으면 코딩, 시간, 사람 중에 코딩에 시간을 더 많이 두는 것일 뿐이다. 연차가 높아질 수록 개발에 주는 영향에서 코딩보다는 시간과 사람에 더 신경을 쓰는 것이다.
발표자는 시니어 이상의 개발자는 개발 조직 전체의 아웃풋을 향상시켜야 한다고 생각한다. 시니어 개발자는 개발팀 전체의 아웃풋에 어떤 영향을 줄 수 있을까?
1. 곱빼기 코딩
시니어 이상의 개발자는 다른 개발자보다 개발 능력이 뛰어날 것이다. 그러나 전체 조직 차원에서 봤을 때 시니어 개발자가 혼자 일을 잘하는 것보다 다른 모든 사람들의 업무 향상을 시켜주는 것이 효율이 많이 나올 수 있다는 것이다. 이때 시니어 개발자의 아웃풋은 없어 보일지라도 조직 전체적으로의 아웃풋은 향상된다.


곱빼기 코딩을 어떻게 적용할 수 있을까?
- 주기적인 리팩토링으로 스파게티 코드 방지
- 좋은 테스트 패턴으로 추후 테스트 작성을 쉽게 유도
- 흔히 할 수 있는 실수를 예방할 수 있도록 Best Practice Guide 작성 및 Linter Rule 적용
- 새로운 기능의 안전한 배포를 위해 A/B 테스팅 프레임워크 도입
- 개발 조직에서 사용하는 기능을 모듈화해, "바퀴의 재발명"을 방지
2. 진명 (眞名)
시니어 개발자는 비즈니스 문제나 기술적 문제의 진짜 이름을 알아내는 사람이라 생각한다.
요구 기능이 생겼을 때 주니어 개발자는 단순히 어떻게 개발을 할까 생각을 해보겠지만, 시니어 개발자는 팀 기술력으로 가능할지, DB가 버틸 수 있을지, 기술 부채가 많은 것은 아닌지 등등 여러 상황을 종합적으로 판단한다. 결국 시니어 개발자는 판단한 내용을 토대로 배경과 문제와 기술적 정의 등을 설명해줘야 한다.
즉, 좀더 넓은 경험과 시야를 토대로 문제를 정의하고 다양한 각도로 문제 해결을 고민하는 입장인 것이다.
3. 정원사
시니어 개발자는 개발팀의 문화를 가꾸는 사람이다. 코드 리뷰나 멘토링을 포함해 테크 토크나 인터뷰와 같은 것도 방법이 있을 것이다.
그러나, 구글에서는 더 나아가 문화를 가꾸려 하고 있다. 예를 들어, 멘토링을 직접 하는게 아니라 더 많은 멘토들이 회사에 있을 수 있도록 멘토링 프로그램을 운영한다. 테크 토크를 주는게 아니라 테크 토크를 할 자리를 마련해준다. 코드 리뷰를 해주는 것 뿐만 아니라 코드 리뷰를 할때의 태도나 매너 등의 것들을 가이드 해준다. 인터뷰도 단순히 하는 것이 아니라 인터뷰를 어떻게 할 것이며 어떻게 채용을 할 것인가와 같은 질문에 답을 해준다.
실제로 구글에서 매년 평가 받는 항목 4가지 중 하나가 "Community Contributions"이다. 모든 사람들이 문화에 기여할 수 밖에 없고 문화에 기여하려 노력하는 구조다. 특히 승진의 필수 요구 사항이다.
절반의 성공, 마이크로 서비스 아키텍처 도입과 조직 구조 - 서주은
회사에 마이크로 서비스 아키텍처(MSA)를 도입하면서 여러 점을 깨달았다. 그중 하나가 MSA는 조직 구조와도 연관이 있다는 것이다.
회사의 조직 구조는 Function 단위의 기능 조직으로 구성되어 있었다. 각 분야별 전문성을 갖는 사람끼리 모여있었다.
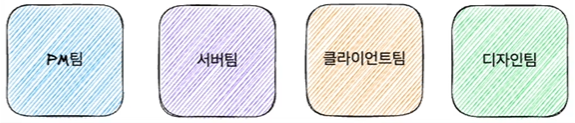
사람이 많아지면서 좀더 확장 가능한(Scalable) 조직 구조가 필요했다. 앞서 다른 세션에서도 언급 되었던 스포티파이의 스쿼드 기반의 조직구조를 갖도록 변경을 시작했다. 한 명의 사람이 하나의 미션팀과 하나의 Function 팀에 속해야 한다. 미션팀은 하나의 목적을 갖고 있는 팀이며, Function 팀은 공통된 전문성을 갖는 조직이다.
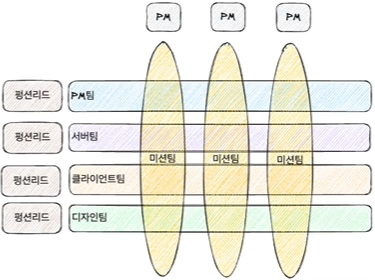
스쿼드 기반의 매트릭스 조직의 단점도 존재하긴 한다. 한 사람이 두 조직에 속해있기 때문에 두 조직의 목표를 동시에 만족시키기 위해 혼란스러운 고민이 있을 수 있다.
또한, 목적 조직(미션팀)을 책임지는 한 명의 엔지니어링 리더가 존재하지 않는다는 점도 단점이다. 서버와 클라이언트간 조율이 필요하거나 PM이 회의가 필요할 때 서버팀 기능 리더와 클라이언트팀 기능 리더와 함께 조율이 필요하다. 서버팀의 리더같은 경우에는 여러 목적 목적 조직간의 조율도 수행해야 한다. 이러한 의사결정 문제가 발생할 수 있다.
그래서 새로운 조직 형태를 갖추도록 변경했다. 기능 조직을 온전히 없애고 미션 조직만을 남기게 되었다. 하나의 제품팀 안에는 Project Manager와 Engineering Manager를 둘 수 있다. 미션 조직만 남김으로써 목표 달성을 추구하는 형태의 조직형태를 갖출 수 있었다. 하나의 제품을 딜리버리하기에 공통된 목적을 갖고 업무를 수행하기에는 좋은 구조라 판단됐다.
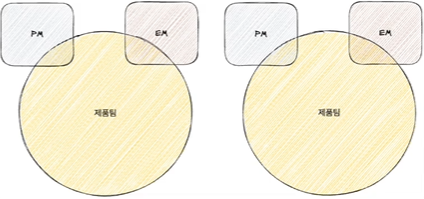
이 조직 구조도 단점이 있다. 예를들어, Engineering Manager 입장에서는 전문 분야가 따로 있을텐데 제품팀 내에 있는 여러 스택의 개발자들을 관리해야하는 부분에서 어려움이 있다.
조직 구조를 이렇게 계속 변경해오는 과정에서 회사가 중요하게 생각했던 가치가 있다.
- 목적 중심
- 자율
목적은 명확하되 자율성을 주어 창의적으로 제품을 발전시켜야 한다는 생각이었다.
스포티파이의 경우에는 팀 생산성에 영향을 준다고 판단된다면 팀 간의 종속성을 최소화시키며 제거해나갔다. 미션팀이 자율성을 갖고 업무를 수행함에 있어 각 팀간의 종속성을 제거하는 것이 필요한 것이다.
<팀 토폴로지>라는 책에서는 IT 서비스 회사를 운영할 때 필요한 조직은 4가지 타입이면 충준하다고 한다. 아래 4가지 타입 중에서 발표에서는 Stream-aligned team과 Platform team을 중점으로 설명한다.
- Stream-aligned team
- 위의 제품팀 또는 미션팀
- 대부분의 팀이 Stream-aligned team이 되어야 함
- 명확한 목표를 갖고 움직이는 팀
- 물고기 잡기
- Enabling team
- Stream-aligned team이 목표 달성을 하는 도중에 만난 장애물을 극복할 수 있도록 도움을 주는 팀
- 물고기 잡는데 어려움을 돕고 스스로 물고기를 잡을 수 있도록 도움
- Complicated Subsystem team
- 높은 수준의 수학적 지식이나 전문 지식을 담당하는 팀 (ex. AI 팀)
- 참치를 잡는 방법을 도와줌
- Platform team
- Stream-aligned team이 목표 달성에 필요한 도구를 제공해주는 팀
- 제품팀을 고객이라 생각하고 서비스하는 조직
- 물고기를 잡는 기계를 개발해 물고기를 쉽게 잡도록 도움
마찬가지로 <팀 토폴로지>에서는 위의 4가지 타입의 팀이 상호작용하는 방법이 3가지의 타입으로 구분할 수 있다고 한다.
- Facilitating
- Enabling team에서 서포트 하는 상호작용
- Collaboration
- 모호하게 정의되어 있지 않은 문제를 해결하고 새로운 것을 찾아 팀간의 긴밀한 협업을 하는 경우
- X-as-a-Service
- 정해진 프로토콜을 명확히 정의하고 잘 사용할 수 있도록 하는 협업
위의 상호작용을 살펴보면 흔히 생각하는 단순 지원성 업무의 상호작용은 없다. 데브옵스나 데이터 인프라 조직은 주로 지원성 업무를 하는 경우가 많은데 더 나아가 플랫폼화해서 지원업무를 벗어나면서도 제품팀이 쉽게 일을 할 수 있도록 하는 업무를 수행한다.
MSA 특징은 다음과 같다. 발표자는 그중 "독립적으로 배포 가능하다"는 점이 가장 중요하다고 생각한다.
- 독립적으로 배포 가능하다.
- 데이터베이스를 공유하지 않는다.
- 느슨하게 결합되어 있다.
- 비즈니스 역량을 중심으로 조직화되어 있다.
- 작은 팀에 의해 소유된다.
- 쉽게 테스트 가능하고 유지관리 된다.

회사에 MSA를 성공적으로 도입시켰다. 하지만 절반의 성공이라고 밖에 볼 수 없다. 1인당 1.57개의 서비스를 담당해야하는 문제가 있었다. 사람마다 다를 수 있겠지만 회사에서는 너무 많은 서비스를 담당하게 되었다고 판단했다. 그러면서 깨달은 점들은 10가지가 있다.
- 마이크로하게 서비스를 나누지 않는다.
- 단순히 책임과 역할이 명확히 구분되는 서비스로 나누는 것에 매몰된다면 서비스를 너무 많이 생산하게 된다.
- 인증을 담당하는 authsvc(인증서비스)와 회원정보를 담당하는 accountsvc(계정서비스)가 있을 때, 역할은 명확하지만 장점도 있지만 현재는 비효율적인 상황이다.
- 서비스 하나를 운영하는 심리적 부담이 생각보다 높다.
- 서비스는 비즈니스 목적에 따라 나누는 것이 좋다.
- 각 서비스마다 리워드 서비스가 존재했는데, 여러 서비스에서 공통적으로 사용할 수 있는 리워드 서비스를 만들기 시작했다. 플랫폼화 시키려 했던 것이다. 결론적으로 어려움이 있었고 리워드 서비스 팀이 해체되고 각 미션 팀으로 합쳐지게 되었다.
- 기능이 같더라도 비즈니스 목적이 다르다면 서비스별로 내부에서 만드는 것이 더 좋을 수 있다.
- 서비스화 대신 라이브러리화 한다.
- Github 전 CTO가 말한 내용이기도 하다. 서비스로 만들기 전에 라이브러리로 만들 수 있는지 한번 고민을 해보고 적용하라는 것이다. 재사용성도 하면서 서비스 운영에 대한 부담감도 낮출 수 있다는 장점이 있다.
- 만들어둔 플랫폼 서비스는 관리하지 않으면 사용되지 않는다.
- API 문서 뿐만 아니라 서비스 자체가 관리가 잘 안된다면 사용하지 않는다.
- 진짜 중복과 거짓 중복을 구분해야 한다.
- 코드가 중복되어 보여도 이후 다른 이유와 다른 속도로 발전하게 되면 다른 코드가 될 것이다. 이런 코드들은 중복으로 합치는 것이 아니라 별도로 관리해야 한다.
- 서비스의 경계를 처음부터 잘 정하기 힘들다.
- 광고 서버와 리워드 서버를 분리한 것을 잘 했다고 생각했다. 광고 도메인은 그 자체로 잘 정의된 상태였고, 리워드 도메인은 광고 도메인에 붙는 부가적인 기능이기 때문에 분리를 진행했다. 광고 서버를 바꿔도 리워드 서버가 잘 동작한다면 완벽할 것이라 생각했다.
- 광고가 송출되는 데 있어서 리워드 발급 여부의 정보가 필요해지기 시작했다. 결과적으로 그냥 광고 서버가 아닌 리워드 광고 서버를 운영해야했기 때문에 리워드 정보 없이 광고 서버가 운영되기 어려웠다.
- 팀과 서비스의 경계는 완벽하게 일치하지 않는다.
- 서비스 특성상 도메인이 여러 군데를 거칠 수 밖에 없다.
- 팀을 분리하고 서비스를 팀에 맞게 분리하는 과정이 오래 걸린다.
- 오너십을 나눌 수 있는 MSA의 장점을 온전히 누릴 수 없다.
- 마이크로 서비스를 도입한다고 소프트웨어의 본질적 아키텍처가 개선되지 않는다.
- 함수 호출이 원격으로 이뤄지는 것일 뿐이다.
- 어떻게 모듈을 나누고 모듈간 간섭을 없앨 것인가가 중요하다.
- MSA가 인터페이스가 명확히 규정되어 있고 인터페이스 추가가 어렵기 때문에 서비스간 느슨한 결합을 유지하기에는 장점이 될 수는 있다.
- Contract test는 생각보다 어렵다.
- 서비스간 통신 과정에서 발생할 수 있는 오류를 미리 찾기 위한 테스트는 개발하고 운영하기 어렵다.
어느 날 고민 많은 주니어 개발자가 찾아왔다 2탄: 주니어 시절 성장과 고민들 - 김영한
Q. 성장을 위해서 어떤 기술을 배워야 해요?
A. 현재 팀에서 사용하는 기술을 배워야 할지 최신 유행하는 기술을 배워야 할지를 묻는 것이라 생각된다. 3종류의 개발자가 있다.
1. 기술 공부를 안 하는 개발자
- 팀에서 동작하는 코드를 보고 비슷하게 짜는 개발자
- 기술에 대한 깊은 이해 없이 개발 업무의 반복
- 기술적 근본 원인을 파악해서 문제 해결하는 것에 어려움
- 팀에서 새로운 기술 도입을 주저함
- 1년치 경험을 10번 반복하는 10년차
2. 기술 트랜드 찍먹 개발자
- 기술 공부를 하기는 하는데 아직 팀내에 사용하는 기술도 이해하지 못함
- 새로운 기술을 도입하고자 한다면 현재 기술의 깊이를 먼저 만들어야 함
3. 팀 기술을 잘 이해하는 개발자
- 팀에서 사용하는 기술 역량을 잘 쌓아둠
- 기술을 잘 이해해 팀 업무를 원활하게 진행
- 팀에 기술 문제가 발생했을 때 원인을 정확히 파악해서 해결
- 팀 내의 신뢰와 기술 포인트 누적
- 결과적으로 평가와 연봉에 반영
팀 기술 학습의 장점
- 동기부여 : 당장 필요한 것을 더 빠르게 학습
- 학습 사이클 : 단순히 이론만 익히는게 아니라 토이 프로젝트와 같은 곳에라도 적용할 필요가 있음
즉, 학습의 우선순위는 다음과 같다.
1. 팀 기술
2. 업계 메인 기술
3. 주변, 최신 기술
단, 기술만큼 비즈니스에 대한 이해도 중요하다. 기술을 이해했다고 바로 비즈니스에 적용할 수 없다. 비즈니스 이해도가 우선이 되어야 한다. 큰 그림으로 상황 전체를 파악할 줄 알아야 한다.
좋은 시스템을 설계하려면 비즈니스 이해가 필수고, 비즈니스를 이해해야 좋은 아키텍처가 설계 가능하다.
업무를 맡을 때 약간의 용기도 필요하다. 자신이 쉽게 할 수 있는 안정적인 업무에서 벗어나 잘 모르더라도 도전적으로 업무를 맡아봐야 한다. 완전히 새로운 영역이어도 좋다. 그래야 점차 자신의 영역이 넓어지고 성장이 가능하다. 본인의 comfort zone을 벗아나야 한다.
Q. 성장하기 좋은 환경이란?
A. 성경에 나온 씨앗 비유와 같다고 생각한다. 씨앗은 콘크리트에서 잘 자랄 수 없고 흙에 있어야 잘 자랄 수 있다. 개발자도 분명 성장하기에 보다 좋은 환경이 있다.
성장하기 좋은 환경이란, 지금 좋다기 보다는 일하기 좋은 방향으로 바꾸어 나가려고 노력하는 조직이라 생각한다. 옛날에는 좋은 조직일 수 있으나 굳어져있는 조직이라면 더이상 도전하기 어렵다. 도전과 고민에 응원을 해주는 조직이 좋은 조직이다.
생각과 고민이 너무 많은 개발자가 나중에 성장할 수 있다. 고민을 많이 해서 개발 속도가 느리다는 개발자에게 3가지를 말해준다.
- 개발 구조 : 항상 최대한 단순하게 생각해야 한다. 생각을 많이 하되 시작은 항상 단순한 형태로 해야 한다. 추상화와 구체화가 적절히 반복되어야 한다.
- 최적화 : 어설픈 최적화가 개발, 유지보수 비용을 폭발적으로 증가시킨다. 최적화도 생각은 많이 필요하지만 최대한 단순하게 진행해 나가야 한다.
- 아키텍처 : 마찬가지..
그 많던 코드는 누가 다 먹었을까: Kotlin multiplatform을 활용한 서비스 런칭기 - 최근호
코틀린 멀티플랫폼이란? 코틀린이 어떤 언어인지로 답변이 될 것 같다.
코틀린이란 단순히 자바를 대신해 사용 가능한 객체지향언어이기도 하면서 실용적인 언어(Pragmatic Language)로 디자인 되었다. 여기서 말하는 실용적인 언어라는 점은 크로스 플랫폼이면서 멀티 패러다임을 지원한다는 것을 말한다.
따라서, 코틀린 멀티플랫폼은 코틀린에 내재된 기능이라 볼 수 있다.
당시 알파버전(현재는 스테이블 버전 발표)이었던 코틀린 멀티플랫폼을 적용한 이유에 대해 알아보자. 스프링을 쓰던 와중에 클라이언트를 담당하던 플러터 개발자가 퇴사를 하게 되었다. 11개월 프로젝트에서 3개월 남은 시점에 발생한 일이라 백엔드는 거의 마무리가 된 상황이었지만 프론트가 거의 개발되지 않은 상황이었다. 그러다보니 안드로이드 클라이언트 개발을 시작(iOS 개발자는 채용으로 대체)하게 되었다.
이러한 상황에서 생산성을 향상시킬 수 있는 방법을 고민했고 안드로이드 개발에 영향도 없으면서 iOS 개발자 합류시 생산성을 극대화할 수 있어야 했다. 그러다보니 자연스럽게 코틀린 멀티플랫폼으로 방향을 정했다.
shared module은 코틀린 멀티플랫폼으로 구현된 모듈이라 생각하면 된다.
맨 처음에 설계했을 때, 우선 클라이언트의 프레젠테이션, 도메인, 데이터 3가지 계층에서 도메인과 데이터 레이어의 구현을 shared module로 진행하기로 생각했다. 프레젠테이션 레이어는 AOS와 iOS가 나눠서 진행하기 때문이다.
문제가 몇가지 있었는데, 첫 번째로 shared module과 네이티브 코드간의 높은 결합도였다. 두 번째는 shared module 관련된 상호 호환성 문제가 있었다. 중첩 제네릭 타입이나 코틀린의 실드 클래스 타입이 기대와 다르게 동작했다. 불필요한 타입체크나 타입캐스팅이 필요하게 되었다.
그래서 다음 두 번째 설계를 진행했다. 네이티브 영역과 결합이 발생하는 것을 피하기 위해, 도메인과 데이터 레이어만 구현하는 것이 아니라 shared module에서 프레젠테이션 영역의 로직까지 구현하도록 했다.
결합도나 타입 호환성이 어느정도 해결 가능했으나, 여전히 만족할만한 수준의 결합도가 아니었다고 판단했다.
다음 세 번째 설계로, 두 번째 설계를 좀 더 개선했다. shared module의 프레젠테이션 로직을 캡슐화하기로 했다. flux라 부르는 단일 뷰 스테이트와 단방향 데이터 흐름을 갖는 아키텍처를 적용했다.
이를 이용해 실제로 결합도를 많이 낮출 수 있었다.
당연히 문제들도 많았다. 특히 대부분의 이슈는 iOS 개발자 입장에서 발생했다.
- Build time overhead (iOS)
- shared module 자체가 xcodebuild 페이지에 추가되어 빌드되며, xcframework가 생성되는 과정이 추가됨
- 약 10분의 오버헤드 발생 -> 개발 및 CI/CD 구축 시 문제 발생
- 해결법 : iOS의 repository를 분리했다. shared module과의 의존성 문제는 안드로이드 repository에서 shared module의 변경사항이 발생시 CocoaPods를 이용해 배포해 iOS repository에서도 사용할 수 있도록 했다.
- Debugging (iOS)
- 최대한 Shared module의 test code를 추가 및 log data를 최대한 포함
- Large codebase
최종적으로 도입했을 때의 장점으로는 생산성 향상에 있었다. 중복 코드를 하나로 관리할 수 있는 장점도 있겠지만 클라이언트 개발자가 업무를 시작할 때 문서의 차이가 더 큰 것 같다. API Docs 보다는 Store Docs를 받아서 개발이 가능했다. API 관점에서 작성된 API Docs는 API를 이해해 클라이언트를 구현하는 데 불필요한 과정이 포함된다. Store Docs의 경우에는 뷰를 기준으로 작성이 되었기 때문에 보다 빠르게 뷰 작업이 완료될 수 있었다.
단점으로는 Shared module 작성 시의 learning curve가 있었다. 일반적인 코틀린 코드를 작성하듯 한다면 상호 호환성이나 메모리 모듈에서 문제가 발생할 수 있다.
점진적 추상화 - 이승천
추가되는 요구사항의 예제(코드)를 통해 추상화에 대해 주관적으로 느낀점을 공유하는 세션이다.
'원화와 달러 입출금을 관리하는 시스템을 구축중인 스타트업 개발자'라는 전제하에 세션을 진행한다.

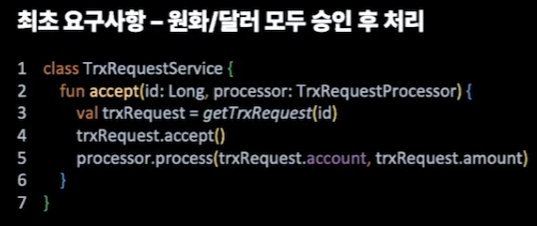
내부 직원이 입출금을 마음대로 할 수 없도록 요청과 승인을 구분지어 개발을 해보자.
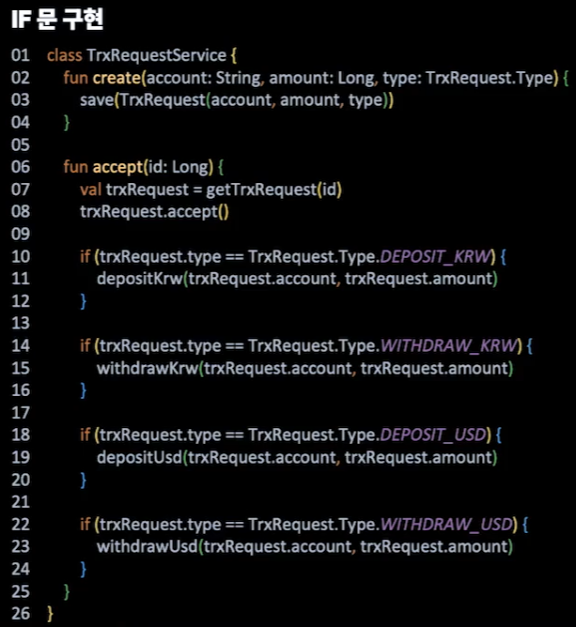
위와 같이 간단히 구현을 했다고 해보자. 위의 코드는 if문으로 분기처리함으로써 OCP에 위배된다. 확장에 좀 더 열려있는 코드 작업이 필요하다.
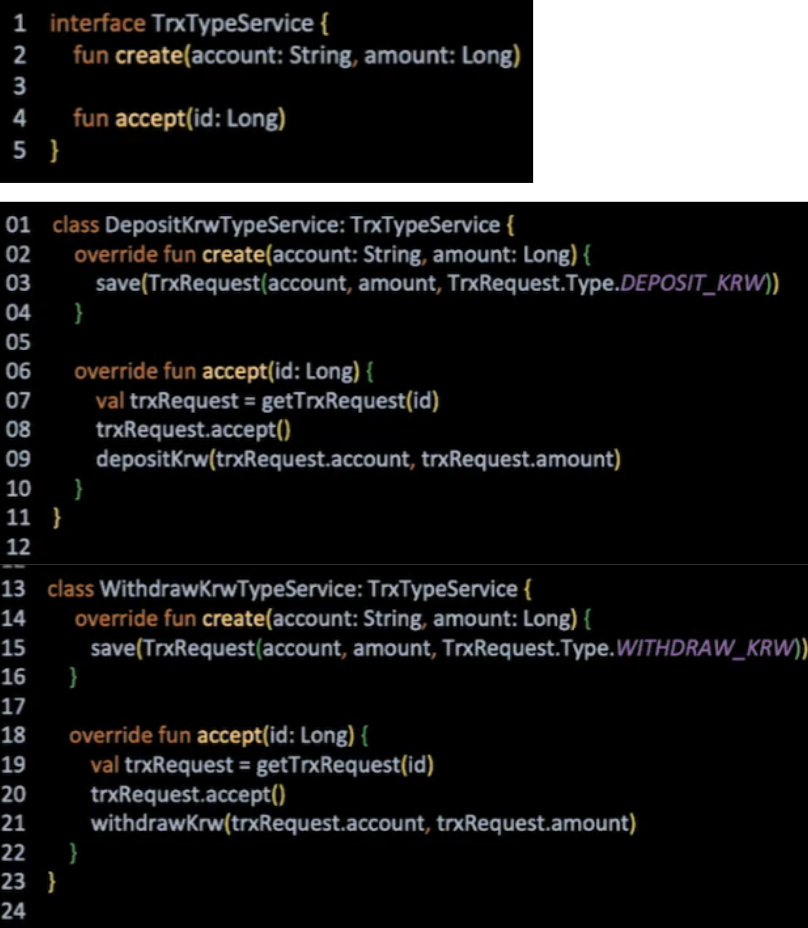
if 분기 로직이 각각 하위 구현체로 로직이 분리되었다. 이제 OCP를 만족할 수 있는 구조로 변화했다.
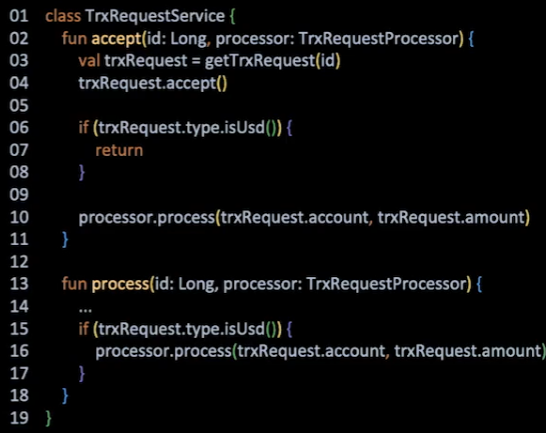
여기에 추가 요구사항이 발생한다.

기존에 if문으로 구현된 모습을 보면, 승인 즉시 처리가 이뤄지고 있는 형태다. if문 구현 코드에서는 달러 코드를 별도 함수로 분리하는 등의 대응으로 즉시 수용 가능하다.
그러나 추상화한 코드에서는 인터페이스가 있기 때문에 인터페이스에 추가된 달러를 위한 함수가 하위 구현체에 모두 영향을 받게 된다. 게다가 원화 입출금의 경우에는 달러 입출금을 위한 별도 함수에서 어떤 처리를 해야할지 막막하다.
즉, OCP를 위해 인터페이스를 도입한 구조는 인터페이스에 구현체를 추가하는 방향으로는 열려있으나 인터페이스 자체의 변경에는 어려움이 존재한다.
이런 일이 발생한 원인은 OCP를 도입한 "축"에 있다. 인터페이스를 도입한 "축"은 원화 입/출금과 달러 입/출금이라는 '타입'이다. 다른 "축"으로는 요청의 생성/승인이라는 '행위'가 있을 수 있다.
앞에서 OCP를 도입할때 인터페이스 추출을 타입으로 가정한 것은 타입이 확장될 것이라 암시적으로 예상했기 때문이다. 그러나 실제로 마주한 요구사항은 행위의 확장이다. 그러다보니 더이상 기존 코드 변경 없이 확장 가능한 구조가 아니게 되며 인터페이스 자체를 변경해야 했던 것이다.
개발 초기에는 소프트웨어가 어느 방향으로 확장할지 예측하기 쉽지 않다. 소프트웨어 발전 방향과 맞지 않는 추상화는 오히려 유지보수에 장애를 일으킨다.
방향을 예측하기 더 쉽지 않기 때문에 추상화 범위를 고민해야 한다.
앞선 예제에서 추상화의 범위를 좁혔으면 어땠을지 살펴보자.
앞선 예제에서는 요청의 생성(create)과 승인(accept)를 전체 인터페이스로 추출했다. 여기서 딱 분기가 필요했던 계좌 입출금 처리 로직만 추상화를 하는 것으로 가정해보자.

이와 같이 너무 넓은 범위의 추상화는 오히려 인터페이스 변경의 위험에 더 많은 노출이 되는 것과 동일하다. 그러니 인터페이스의 추상화는 필요한 만큼만 수행해야 한다. 추상화의 범위에 따라 인터페이스의 이름도 메소드도 바뀔 수 있다.
요구사항은 계속해서 추가될 것이기 때문에 추상화를 언제 수행할지도 고민해야 한다.
하나의 함수에서 구체적인 흐름이 명확히 보이고 묶을 수 있는 단위가 보이기 시작할때 추상화를 시작하면 된다.
인프런에서는 수천 개의 테스트 코드를 이렇게 다루고 있어요 - 이민우
과거 회사에서 테스트 코드 없이 제품 코드만을 작성하던 발표자가 인프런에서 입사 후 테스트 코드를 작성하는 방법에 대해 깨닫고 테스트 코드를 작성하고자 또는 도입하고자 하는 개발자들을 대상으로 공유하는 세션이다.
1. 테스트를 왜 해야할까?
레거시 코드를 받아봤을 때 잘 익혀지지 않아 동작이 이해되지 않는 경우가 있다.
레거시 코드를 수정할 때마다 버그가 이곳 저곳에서 발생하기도 했다. 그러다보니 코드 수정에 자신감이 없어졌다.
마지막으로 버그 수정을 하려고 해도 어디에서 문제가 발생한 것인지 파악이 어려웠다.
이 모든 문제들은 테스트로 해결이 가능하다.
레거시 코드가 잘 익혀지지 않는 점은 코드의 복잡함과 나쁜 가독성에 원인이 있다. 이 부분은 클린코드와 리팩터링으로 해결이 가능하지만 근본적으로 "코드의 문서화"가 이루어지면 간단히 해결될 수 있다. 테스트를 도입한다면 테스트 명세를 통해 문서화가 가능하다.
정상 동작인 Happy Path 부터 예외 상황인 Edge Case 모두 테스트 명세서로 기록 가능하다. 테스트 명세는 실제 기능에 대한 다양한 동작을 기록하는 역할이다. 따라서 테스트 코드 명세만 보더라도 코드가 동작하는 방식을 파악할 수 있다.
코드 수정시 이곳저곳 버그가 발생한 것은 하나의 기능이 다른 기능과 협력관계가 있었기 때문이다. 변경 여파를 파악하지 못해 회귀 버그가 발생한 것이다. 기능의 구성요소간 상호작용은 필수적으로 이뤄질 수 밖에 없기 때문에 사전에 차단하고 예방하기 보다는 관리하고 대처하는 방식이 필요하다. 즉, 회귀 테스트가 지속적으로 필요한 것이다.
어느 코드에 문제가 있는지 발생했는지 파악하지 못한 것은 코드의 복잡성 때문이다. 잘못된 설계와 객체 간의 의존성으로 인해 문제 해결을 위한 디버깅 시간이 늘어나는 것이다. 만약 우리가 만든 기능에 대한 테스트 코드를 작성하기 어렵다면 제품 코드가 의존성 자체가 높은 코드이거나 설계가 잘못된 확률이 매우 크다. 따라서 테스트 코드 존재만으로 제품 코드의 검증 뿐만 아니라 설계와 의존성이 적절한지 파악할 수 있다.
2. 테스트를 왜 해야할까?
지속 가능한 서비스를 위해, 그리고 지속 가능한 서비스를 개발하는 나를 위해
3. 테스트를 어떻게 해야할까?
발표자는 테스트를 3가지 계층으로 나눠서 작성한다.
- 단위 테스트
- 단일 동작 단위에 대해 작성된 작은 코드 조각 검증
- 시스템 의존성 없이 테스트 가능한 단위
- 의존성이 없어 작성이 쉽고 빠르게 테스트 가능
- 비즈니스 핵심인 도메인 객체, 복잡한 연산의 알고리즘 객체, 유효성 검증과 데이터 포맷의 DTO 객체 등
- 통합 테스트
- 시스템 의존성과 상호작용을 검증
- 기능에 대한 유즈케이스 및 엣지케이스(예외케이스)
- 데이터베이스와의 상호작용, MSA 서비스간 상호작용 등
- E2E 테스트
- 시스템 전체의 흐름을 검증
- 가장 현실성 있지만 작성하기 어려운 테스트
- API 테스트 등
테스트 단계별로 목적과 특징이 다르다. 그중 통합 테스트는 좀 더 세분화해서 알아볼 필요가 있다. 비즈니스 시나리오 검증을 위해 시스템 의존성과 상호작용을 검증하는 통합 테스트는 시스템 의존성이라는 것이 범위가 넓기 때문이다. 시스템 의존성은 시스템간의 의존성일 수도 있고 하나의 시스템 안에서 일어나는 의존성일 수도 있다.
내부 의존성은 스스로 제어 및 관리가 가능하다. 또한 올바르게 동작하는지 검증할 대상이 된다. DB가 대표적인 예가 될 수 있다. 반면 외부 의존성은 제어할 수 없는 영역이다. SMTP, HttpClient와 같은 것들이 있을 수 있다.
내부 의존성을 테스트할 때는 실제 객체를 이용해 접근한다. 그러다보니 팀원들이 모두 같은 환경을 공유하면 테스트가 깨지기 쉬워진다. 내부 의존성 테스트 환경은 공유환경을 이용하지 않고 로컬라이징해서 테스트 환경을 분리 및 격리시키는 것이 좋다. 또한, 여러 테스트 케이스가 상호 독립성을 갖기 위해 setup에서 공유 자원을 항상 초기화시켜줘야 한다.
외부 의존성을 테스트할 때는 실제 객체가 아닌 가짜 목업 객체를 이용해 의존성 대상을 격리시킨다. 지나친 모킹은 테스트의 목적과 다른 방향으로 흘러갈 수 있기 때문에 주의해야 한다. 세부 구현에 대해 지나치게 의존적인 테스트는 올바르지 않다고 판단해 목킹을 자제하고 있다. 마찬가지 이유로 스텁 객체를 사용하기도 한다.
발표자의 경우 최대한 실제 객체를 사용하고 그러기 어려운 경우 모의 객체를 사용한다. 다만 실제 객체를 사용할 경우 테스트 속도가 현저하게 떨어지기 때문에 주의해야 한다.
4. 테스트를 어떻게 개선할까?
발표는 TS 관련된 내용이지만 최대한 포괄적으로 요약해보면 다음과 같다.
- 컴파일러와 프레임워크를 고민해보자.
- 인메모리 데이터베이스를 고려해보자.
- CI 테스트 단계에서 테스트 속도를 높이자.
- 병렬 테스트(단위/통합/E2E)로 CI 파이프라인의 효율성을 개선하자.
- 단위 테스트의 비중을 통합 테스트나 E2E 테스트의 비중을 더 두어 빌드 속도를 감소 시키자.
- 프로젝트가 모노레포 방식으로 관리된다면 각각의 모듈을 독립적으로 테스트하는 것을 고려하자.
팀플레이어 101: 팀의 성공을 위해 달리는 메이커 되기 - 진유림
발표자는 여러 스타트업을 다녀보면서 다양한 규모에서 다양한 성향의 사람들을 많이 만나봤다. 그러면서 단순히 코딩만 잘한다고 좋은 개발자가 되는 것은 아니라고 느꼈고 함께 일하고 싶은 사람과 팀에 임팩트를 줄 수 있는 사람이 어떤 사람인지 고민했다.
코딩은 개발자의 업무 중 일부이며 실제로 하는 일은 매우 많다. 연차가 쌓일수록 코딩 보다는 코딩 외의 개발 작업에 더 많은 시간을 할애하게 된다.
발표자는 1.5년이라는 시간동안 훌륭한 동료의 좋은 점을 따라하기 위해 Best Practice 61개를 수집했다. 타인의 팀프레이어다운 행동을 수집했으며, 수집 기준은 '멋있다'가 전부다. 대신 따라하기 쉽도록 '액션 아이템'의 형태로 수집했다. 추가적으로 '반면교사'의 내용도 수집했다. 주변에 따라할 사람이 없다면 반대로 따라할 사람이 많다고 생각해보자!
수집한 키워드를 분류해보니 3가지 타입으로 분류가 가능했다.
- 본질
- 관계
- 속마음
각 내용별로 실제 사례를 중심으로 확인해보자.
1. 본질을 알아야 한다.
PM : "신분증 인증에서 사용자가 많이 나가네요. [내일 입력하기] 버튼을 추가하면 어떨까요?"
나 : "좋아요 ^^ 프론트 공수는 얼마 안들어요~"
1차적으로 요구사항을 검토한 것으로 다소 아쉽다.
팀플레이어 : "토스 인증서 활용 동의를 받으면 신분증 인증 자체를 스킵할 수 있을 것 같아요. 법무팀 검토 부탁드려볼게요."
현재 상황의 근본 문제를 파악해 전문성을 더한 답변을 제시했다. 이것이 개발자가 기획안보다 창의적으로 문제를 해결한 케이스다.
즉, 코딩은 전부가 아니고 아래의 업무의 일부분이다.
- 맥락을 파악하고
- 본질을 꿰뚫고
- 전문성을 더해 해결책을 보강
다른 사례를 봐보자.
상황 : 개발 버그로 금액 장애가 빈번히 발생하는 상황
대응 : "실수했네요. 더 신경쓰겠습니다." → 액션으로 테스트 코드 추가
문제상황을 1차원으로 검토해서 아쉬운 대응이다. QA를 제대로 수행하지 못한것인지 정확환 원인 파악을 수행하지 않았다는 점에서 아쉬운 것이다. 원인 파악을 제대로 수행하지 못했기 때문에 테스트 코드를 작성하더라도 문제가 재발할 수 있다.
팀플레이어 : "출시 후 1년동안 제품 복잡도가 지수적으로 높아졌습니다. 기능 추가 비용이 커지고 수정에 취약한 코드가 되었습니다. 지난 주의 버그는 자칫 N억원의 손실을 발생시킬 수 있었습니다. 팀 차원에서 리스크의 심각성을 인지하고 해결책을 논의해보면 좋겠습니다."
맥락을 전달하면서 문제를 투명하게 드러내 팀원들의 맥락을 모을 수 있도록 했다. 그러면 팀원들로부터 다양한 관점에서 의견을 전달받을 수 있다. 문제를 바라보고 대응책을 일정 관점, 최소 테스트 관점, QA 환경 개선 관점 등으로 고려해보고 의견을 취합할 수 있다.
문제를 근본적으로 해결하기 위해서는 코어 원인을 찾아야 한다.
- 혼자 고민하지 말고
- 팀 차원에서 공감대를 형성하고
- 목표 달성을 위한 최선의 방법 조사
2. 관계를 알아야 한다.
PM : "외부사 API 완료일이 늦어졌습니다. 일주일 더 필요한데 릴리즈 일정 괜찮을까요?"
나 : "저희 일정도 늦어지죠... 저희도 일주일 추가하면 될 것 같습니다."
일정 지연이 유발하는 문제를 고민하지 않고 수동적으로 일정을 미룬 점이 아쉽다. 즉, 응답이 오히려 일정을 더욱 불확실하게 만들었다. PM은 분명 또 일정이 미뤄지는 것에 대해 걱정할 것이다.
팀플레이어 : "외부사 API가 늦어도 X일까지 되지 않으면 버퍼로 잡아둔 목표일 Y일까지는 불가능해요. 스펙을 줄여서 Y일에 맞추던지 일정을 조정해야 합니다."
외부사와 스펙 사이의 의존 관계를 명확히 드러냈다. 일정을 맞추기 위한 대응책도 함께 제시한 좋은 답변이다.
다른 사례를 봐보자.
상황 : 디저이너에게 받은 시안 중 굉장히 복잡한 페이지가 1개 있다. 하지만 개발 리소스가 부족한 상황이다.
대응 : 일정을 정해보지만 일정에 쫓겨 야근을 한다.
수동적으로 디자인을 검토해 긴 개발 일정을 잡고 그마저도 야근으로 끝내는 상황이다. 개발 비용도 크고 일정에 쫓겨 개발했기 때문에 향후 유지보수 비용이 증가할 가능성이 높다.
팀플레이어 : "2주 가량 걸릴 큰 스펙이네요. 여기서 X, Y는 동일한 목적의 기능인 것 같은데, 어떤가요?"
"둘을 간소화해 개발 및 운영 공수를 줄이면 이번 주 내로 빠르게 오픈할 수 있습니다. 오픈 후 데이터를 보고 발전시키는 것은 어떨까요?"
기능의 역학관계를 파악한 뒤 개발 리소스의 맥락을 더해 에자일한 방안을 제시한다.
즉, 다음과 같이 정리할 수 있다.
- 임팩트에 비해 공수가 큰 작업은 중요도를 파악해 적극적으로 스펙을 줄여야 한다.
- 개발 공수를 투명히 전달해 팀이 올바른 결정을 할 수 있도록 해야 한다.
- 한 번에 여러 기능 개발이 필요하다면 각 기능의 의존관계를 파악해 데이터 기반으로 끊어서 배포한다.
3. 말하지 않은 것을 알아낸다.
상황 : 동료가 어떤 생각을 하는지 궁금하다. 지금 업무가 커리어에 도움이 된다고 생각할까? 팀을 옮기고 싶어할까?
질문 : "요즘.. 잘 지내세요..?"
위 질문을 받은 사람은 생각을 검열하고 답변할 수 밖에 없다. 요약해서 답변하기도 하며 구체적인 이야기로 들어갈 수 없다.
팀플레이어 : 위클리(또는 원오원)에 [역량 체크인] 템플릿 도입을 검토한다.
1. 최근에 해본 노력
2. 못하고 있어 아쉬운 것
3. 블로커
동료에게 먼저 물어보지 않고도 먼저 말할 수 있는 장치를 마련
스스로 회고를 통해 자신의 시도(긍정)와 욕구(아쉬움)을 마주하도록 했다. 이것만으로도 답답함이 해소될 수 있다. 게다가 다른 동료도 공감을 한다면 더 풀릴 수 있다. 조직적 문제라면 협력해서 해결할 수도 있을 것이다.
팀원 입장에서 다른 사례를 살표보자.
상황 : 성과가 잘 안나고 있는 것 같다. 하는 일 이상으로 팀의 성과를 폭발시킬 수 있는 방안은 없을까? 거시적 관점에 있는 PM에게 물어보자.
질문 : "요즘 XX한 문제가 있는 것 같아요. 해결하기 위해 제가 할 수 있는 일이 있을까요?"
PM이 평소에 고민해본 질문이 아니라면 의미있는 답을 해주기 어렵다. 답변도 XX 문제에 대해 집중되어 그것 이상의 문제에 대해 얘기할 수 없게 된다.
팀플레이어 : "요즘 일할때 XX가 잘 안된다고 느껴져요. PM님은 어떠세요"
PM이 관련 고민과 시도를 쉽게 답변할 수 있다. 고민을 먼저 오픈하고 상대방의 최근 생각을 이끌어내면 문제에 공감대를 맞추고 최선의 해결책을 찾아낼 수 있는 방법을 찾을 수 있다.
즉, 다음과 같이 정리 가능하다.
- 포괄적 질문은 포괄적 답변을 이끌어낸다.
- 상황을 쉽게 떠올릴 수 있도록 질문하자.
- 커뮤니케이션에 대한 철학을 말해주세요
→ 지난 프로젝트에서 동료가 어려움을 겪었을 때 어떤 행동을 하셨나요?
- 커뮤니케이션에 대한 철학을 말해주세요
- 상황 파악하기 전까지 판단을 유보해 두는 것이 진실을 찾을 수 있는 방법이다.
관련해서 가치관 형성에 도움을 주었던 재밌게 읽었던 책 3권이다.
- 성과 향상을 위한 코칭 리더십
- 판단하지 않는 힘
- 소프트웨어 장인
함수형 프로그래밍 3대장 경험기: 클로저, 스칼라, 하스켈 - 김대현
함수형 프로그래밍 언어에 특징에 대해 살펴보자.
우리가 일반적으로 사용하는 언어들은 보통 명령형 프로그래밍 언어다. 어떤 메모리나 상태값, 객체의 인스턴스 멤버 변수의 상태값을 읽어서 명령얼 처리한 다음 다시 값을 엎어쓰는 방식으로 진행된다. 이 과정을 반복해 원하는 결과값을 뽑아낸다.
함수형 프로그래밍의 경우에는 바뀌지 않는 인풋값을 받아 함수 처리를 진행하면 또 다시 바뀌지 않는 불변값을 반환받는다. 이런 작업을 연쇄적으로 수행하게 된다.
함수형 프로그래밍의 매력은 다음과 같다.
- 지금까지의 일반적인 프로그래밍 언어에도 함수형 특징이 도입되고 있다.
- 평소 개발에도 함수로 분리하는 작업은 깔끔 + 유연 + 탄탄한 개발 경험을 제공한다.
- 더 나은 코드를 작성해 더 훌륭한 개발자가 될 수 있다.
- 재밌다.

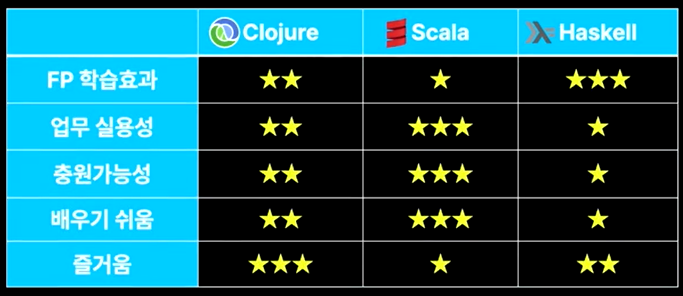
특징이 매우 많지만 그 중에 몇개만 적었다. 이 중에서도 모두 설명하기에는 시간이 부족해 언어별로 설명하기 편한 것들을 선택해 설명한다.
요약 내용에는 해당 내용은 빼고 언어별로 간단하게만 적는다.
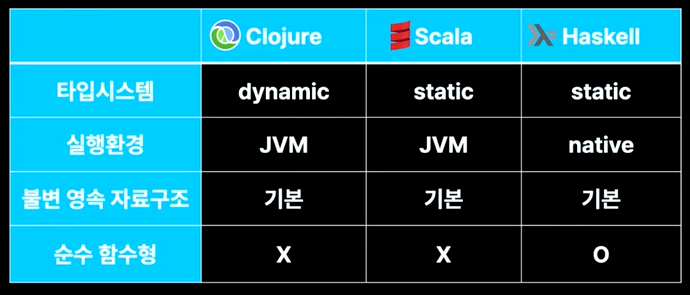
1. Clojure
- 2007년 공개된 현대판 LISP
- JVM 환경
- <해커의 화가> 책을 읽고 LISP에 관심을 가져 공부하기 시작
- (주관적) 가장 간결하고 우아한 언어
- (주관적) 겉모양새(괄호의 중첩)가 독특해 거부감 및 두려움이 있는편
- 연산자의 우선순위가 없고 모든 것이 함수 호출만으로 이루어져있으며 괄호로 감싼 우선순위만 존재해 서브 함수를 수행
- 함수를 변수와 같이 반환을 통해 고차 함수 사용 가능
- 함수는 입력과 출력이 명확하고 부수 효과가 없어, 입력값에 대한 출력값 테스트가 편리
- 공통된 함수를 고차 함수에 넘길 수 있어 유연하고 간편한 공통코드의 재활용
2. Scala
- 2004년 공개된 OOP(객체지향 프로그래밍) + FP(함수형 프로그래밍)
- multi paradigm 언어
- 보통 OOP와 FP는 베타적인 것으로 오해하지만 그렇지 않은 반례로 보면 됨
- JVM 환경
- Clojure로부터 명령형 프로그래밍 언어에 관심이 이어져 공부
- <순수 함수형 데이터 구조> 책 추천
- 불변영속 자료구조의 특징 (함수형 프로그래밍 언어의 특징)
- (주관적) 비교적 일반적인 명령형 프로그래밍 언어와 별다르지 않은 모양새
- (주관적) 현업 함수형 프로그래밍 언어에 최적
- (주관적) 타입 추론이 강력해 정적 타입 프로그래밍으로도 꽤 괜찮은 언어
- (주관적) 객체지향 지식을 함께 활용하는 점이 매력적
- 불변 영속 자료 구조 : 데이터 자체를 한 번 만들면 프로그램 생명 주기가 끝날 때까지 바뀌지 않는 성격
- 불변 데이터 → 멀티 스레드 안전성
- 영속 데이터 → 데이터 중복이나 메모리/시간의 복잡도 증가 패널티 보완
- 함수형 언어는 주로 싱글 링크드 리스트를 자료구조로 많이 사용
- 맨 뒤에 데이터를 추가한다면 기존 리스트를 차례대로 복사하다가 마지막에 요소를 하나 추가로 붙이는 식으로 작업한다.
- 원래의 데이터는 변하지 않고 새로운 데이터를 생성한다. → 시간복잡도 O(N)
- 기존 리스트의 앞에 붙이는 건 시간복잡도가 좋다. 앞에 추가된 요소를 가리키면 새로운 b인 것이고, 기존의 맨 앞의 데이터를 가리키는 건 기존의 a가 된다. (즉, 복사해 생성하지 않음)
- 불변영속 자료구조는 멀티 스레드에서 상태를 공유할 때 매우 안전
3. Haskell
- 앞의 것들보다 가볍게 참고만 하자
- 순수 함수형 프로그래밍 언어
- Monad로 부수 효과를 다룸
- 함수형 프로그래밍 언어 학계의 사실상 표준 언어
- 정적 타입 + 막강한 타입 추론
- 별도 VM 없이 컴파일(JVM 에코 시스템 지원 X)
- (주관적) 모나드를 너무 많이 배워야해 훈련이 되는 긍정적인 측면과 주객이 전도되는 것과 같은 부정적 측면
- (주관적) 학계 언어이다보니 실무 라이브러리가 부족
- 참조 투명성
- 특정 시점, 문맥 관계 없이 어떤 식을 고정된 값으로 평가 가능
- 함수 입력값이 같다면 언제나 결과가 동일
- 값과 식을 치환해도 무방
- 등식 추론으로 코드 검증이 쉽고 증명 가능

클로저 언어는 LISP 언어라는 것 자체가 레벨업에 도움을 준다.
참고로 Rust도 꽤나 함수형 언어라 생각한다.
우리는 이렇게 모듈을 나눴어요: 멀티 모듈을 설계하는 또 다른 관점! - 조민규
기존의 프로젝트를 모듈로 나누면서 모듈을 나누는 기준에 대한 내용이 부족했다. 모듈을 나누는 기준을 현재 시스템에 맞춰 정리하고 적용했던 기준을 공유하는 세션이다.
단, 모듈을 설계하는 사람과 해결해야할 문제에 따라서 모듈 설계는 언제든지 달라질 수 있다.
회사에서 담당하던 업무는 기존에 멀티 프로젝트 구조였다. API, 인증/인가 게이트웨이, 통계를 위한 배치, 관리를 위한 Admin, 공통 모듈 Common으로 구성되어 있었다. Common은 의존성 관리, 엔티티 관리, 서비스(애플리케이션) 계층 관리를 맡았다.
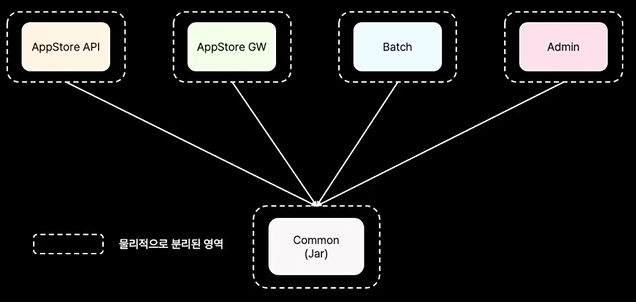
이 구조에서는 아래의 문제가 있다.
- 작업 수행 및 히스토리 파악의 어려움
- Common과 다른 프로젝트가 별도로 관리되기 때문에 Common이 선배포되어야 함
- 작업 중인 프로젝트간 스위칭이 발생하는 경우가 발생
- 하나의 히스토리가 여러 프로젝트에 퍼져있음
- 서비스 분리의 어려움
- MSA가 항상 좋은 것은 아님
- 시스템이 커지면서 서비스 분리가 필요한 경우가 있을 경우 분리가 어려움
- "결합을 분리하되 서비스가 되기 직전에 멈춘다. 가능한 한 오랫동안 동일한 주소 공간에 남겨두면 서비스에 대한 선택권을 열어둘 수 있다." - 로버트 C. 마틴
- 로버트 C. 마틴의 말에 공감해 이해관계자를 바탕으로 모듈을 나누는 기준으로 선정
- SRP 위반 가능성
- "SOLID 원칙 중 가장 의미가 잘못 전달된 원칙이 SRP 다." - 로버트 C. 마틴
- 하나의 일만 수행하는 것이 아닌, 변경의 이유가 하나여야 함을 의미하며 하나의 액터만을 책임져야 함을 의미
- Common 변경이 어려움
- Common을 수정하는 모든 프로젝트에 영향이 가게 됨
- Common의 변경이 어려워지면 점차 데드코드가 늘어나 레거시가 됨
- Common 배포 의존성
- 배포 독립성(변경된 특정 컴포넌트만 다시 배포 가능)과 개발 독립성(각 모듈을 독립적 개발 가능)이 확보되어야 효율적 업무 수행 가능
- Common 라이브러리 선배포가 항상 필요하기 때문에 재빠른 대처가 어려움
위의 문제들을 원인으로 멀티 모듈 구조로 변경하기로 결정했다. 아래와 같은 구조로 결정을 했으나 앞서 말했듯 모듈을 나누는 구조는 항상 달라질 수 있으니 나누는 과정에 집중하자.
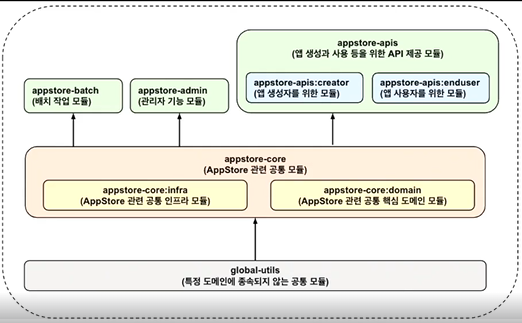
모듈을 나눌 때 어떤 모듈부터 나눠야 할까? 가장 단순한 것부터 시작하는 것이 좋다고 생각해 공통 코드를 분리하기로 결정했다. 공통 코드 중에서도 시스템 독립적인 코드를 먼저 작업을 시작했다.
이 코드들은 도메인에 무관한 코드가 거의 없어 변경이 거의 없을 모듈에 해당했다. 대부분 유틸성 작업의 클래스였다.
다음은 시스템에 종속적인 공통 코드를 분리하기로 했다. 이때 도메인 공통 코드와 인프라 공통 코드로 나눠서 세분화해 분리했다. 도메인에는 도메인 엔티티, 유스케이스 등이 해당되며, 인프라에는 웹, 데이터베이스, 캐시 등이 해당된다.
참고
* 핵심 비즈니스 로직 : 시스템 유/무 상관없이 존재하는 비즈니스 로직
* 핵심 비즈니스 데이터 : 핵심 비즈니스 로직에서 사용하는 데이터
* 도메인 객체 : 핵심 비즈니스 로직과 핵심 비즈니스 데이터는 뗄 수 없는 관계로, 이 둘을 묶어서 관리하는 개념
* 유스케이스 : 시스템이 반드시 있어야 존재 가능한 비즈니스 로직
도메인과 인프라는 서로 다른 수준(level)로, 서로 다른 변경의 속도를 갖기 때문에 이 둘에 대한 기준으로 세분화 작업을 숳애했다.
수준(level)은 입력(HTTP, 웹소켓 등)과 출력(캐시, 데이터베이스 등)까지의 거리다. 고수준은 입력에서 출력까지 거리가 먼 것을 의미하며 저수준은 반대로 거리가 가까운 것을 의미한다.
고수준은 비즈니스 요구사항에 의해 수시로 변경되는 특징이 있으며, 저수준은 새로운 환경 또는 보안 취약점 등에 의해서만 특정 시점에 변경되는 특징이 있다.
그 다음 기능에 따라 모듈을 나눴다. 기능별로 필요한 의존성이 서로 달랐기 때문이다.
마지막으로 서로 다른 액터를 기준으로 나눴다. SRP를 위반하지 않기 위함이었다.
멀티 모듈 설계시 고려했던 사항이다.
- 유스케이스를 공통 모듈에 담지 않기
- 사이드 이펙트 발생 원인은 SRP 위반이다.
- Common 공통 모듈에 있던 유스케이스 비즈니스 로직이 SRP 위반을 유발한다.
- 우발적 중복 코드(Accidental Duplication)을 의심해서 액터가 다를 경우 중복을 유지해야 한다.
- 진짜 중복인 경우에는 공통 API를 만들거나 중복을 허용했다. 코드 공유는 절대 하지 않았다.
- 자동 빈 스캔 방식 사용하지 않기
- 공통 모듈에 존재하는 인프라 구성을 제한한다.
- 인프라 구성 및 빈 자동 등록을 하기 위한 @ComponentScan는 오히려 인프라 구성을 제어할 수 없게 만든다.
- 해당 구성이 필요하지 않는 서비스도 모두 인프라 구성 설정이 강제된다.
- 엄격히 공통 모듈 관리하기
- 언어(가시성 문법 등) 또는 빌드 도구를 활용한 컴파일 제한
- 빌드 도구 또는 ArchUnit 라이브러리 등을 이용한 빌드 제한
- Merge 최소 approve 수 제한 등
- 기타 Github Actions 이용해 모듈 라벨링 등
- 많은 결정 사항들을 미루기
- "좋은 아키텍트는 결정되지 않은 사항들을 최대화한다." - 로버트 C. 마틴
- apis 모듈을 서비스로 분리하는 것은 관리 포인트와 비용이 늘어남을 말하는 것이기 때문에 단순한 선택사항이 아닌 생존의 기로에서 분리 여부 판단이 필요
- global-utils 모듈의 라이브러리화(jar 업로드)는 사내 저장소를 별도로 관리해야 하기 때문에 신규 프로젝트가 생길때 결정
- 테이블 설계를 미뤄야 DBA를 통해 테이블 변경 요청 횟수도 적어질 수 있음
- 많은 결정사항들은 1회성 결정사항이 아니며 애플리케이션이 확장되면서 수시로 검토해야 함
시니어 개발자 너머의 성장: 대규모 조직을 위한 스태프 엔지니어(Staff Engineer) - 남상수
"나는 매일 조금씩 성장하고 있을까?"
새로운 기술과 분야들도 많이 나옴에 따라 뒤쳐지고 있는 것은 아닐지 고민하게 된다. 나는 진정으로 성장하고 있는 것일까 아니면 익숙한 프로젝트들을 계속하고 있는 것일까?
개발자가 스포티파이에서 경험한 조직 개발자(스태프 엔지니어)로 성장한 경험을 나누는 세션이다.
어떻게 성장을 하는가?
성장을 이야기할 때 성장 사고 방식을 빼놓기 어렵다. 성장 사고 방식에는 고정 마인드셋(Fixed Mindset)과 성장 마인드셋(Growth Mindset)이 있다. 고정 마인드셋은 누구나 정해진 만큼의 재능과 능력을 지닌채 태어나 자질이 고정되었다는 생각이다. 그러다보니 실패하더라도 자신은 능력이 없기 때문이라 생각해 노력을 더 하지 않는다. 성공할만한 것에 집중하고 새로운 학습과 경험에 회피하는 특징을 갖는다.
반대로 성장 마인드셋은 능력이 가변적이라 노력할수록 발전할 수 있다고 생각하는 것을 말한다. 결과보다 과정에 집중해 실패를 능력을 키울 수 있는 시간으로 생각한다.
기업에서 개인의 생장은 어떻게 이뤄질까?
70-20-10 학습 모델이라는 것이 있다. 업무 경험을 통해 스스로 문제를 해결하고 결정하며 실수로부터 배우면서 성장하는 것이 70%, 관계를 통해 다른 동료와 멘토의 피드백과 조언이 20%, 공식적인 교육을 통해 10% 성장이 구성되어진다는 것이다. 즉, 공식적인 교육보다는 업무에서 더 많은 성장이 가능하다는 것이며 보다 능동적인 문제 해결과정에서 성장이 이뤄지는 것을 말한다.
성장하고 있는지 어떻게 알 수 있을까?
개발자의 성장은 인식하기 어렵다. 성장의 정도를 인식하거나 객관화하기 어렵기 때문이다. 그러나 우리는 회사 업무를 하면서 자연스럽게 비슷한 기능과 프로젝트들을 반복하면서 성장하게 된다. 하지만 이 성장이 더이상 없거나 속도가 너무 느리다고 느껴질 때가 있다.
나는 계속 성장하고 있는 걸까?
70-20-10 학습 모델에서 말한 것처럼 대부분의 성장은 실제 업무를 진행하면서 관련 지식 탐색, 기술 개선, 문제 해결 과정을 겪으며 이뤄진다. 회사 프로젝트는 조금씩 차이가 있겠지만 자신의 업무는 점차 차이가 없어지는 경우도 많다.
익숙함을 넘어선 성장을 위해서는 현재 업무 이상의 성장 방향에 대한 생각이 필요하다. 스터디 그룹이나 교육으로도 가능하지만 해당 방식보다는 업무 방향이 성장 방향과 일치할 때 더 효과적인 성장을 할 수 있다.
어떤 일을 하는가?
성장 방향은 CTO를 일반적으로 생각할텐데 조직 규모나 모습에 따라 하는 일은 다를 수 있다. 따라서 성장의 방향은 직함보다는 역할에 맞춰야 한다.
업무를 통해 성장시킨 능력은 일정 수준부터는 잘 성장하지 않는다. 이때 이를 넘어서는 영역은 시니어 개발자다.
시니어 개발자는 무엇을 하는가?
사내 다른 시니어 개발자분들에게 인터뷰하는 것도 방법일 수 있다. 발표자가 추천하는 방법은 회사에서 추구하는 역할에 대해 살펴보는 것이다. 예를 들어 채용 공고를 살펴보는 것이다.(이 방법은 채용 공고에서 원하는 역할을 명확히 적는 회사만 해당될 것 같다.)
스포티파이의 경우 교차 기능 조직으로 구성된 애자일 팀 단위로 구성된다. 따라서 시니어 개발자 채용 공고에 아래와 같은 역할이 강조된다.

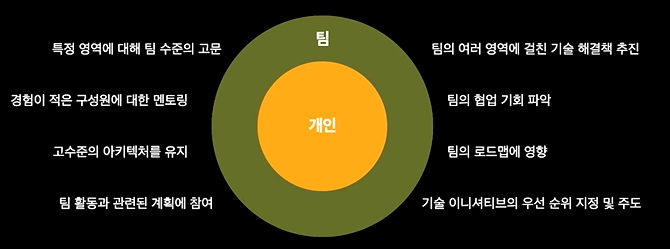
시니어 개발자 이후에는 어떻게 성장해야 할까?
나는 무엇이 하고 싶은가?
또다시 성장의 방향에 대해 고민해야 한다. 개인이 추구하는 방향에 따라 다양한 길이 있다. 새로운 기술과 미래 가치나 본인의 희망에 따라서 분야를 옮길 수도 있다. 다른 분야로 옮기게 되면 해보지 않은 다양한 지식과 기술이 많이 존재한다. 아니면 다른 팀으로 새로운 프로젝트를 맡도록 옮길 수도 있다.
개발자가 아닌 관리자의 길을 선택할 수도 있다. 관리자는 새로운 팀원을 고용하고 엔지니어링 팀을 감독하며 팀의 교육을 지원하는 역할이다.
개발자의 길은 위와 같이 크게 개인 기여자(개발자)와 관리자로 나뉘게 된다. 발표자의 경우에는 개인 기여자의 길을 선택했으며 시니어 엔지니어를 넘어서 스태프 엔지니어를 선택했다.
스태프 엔지니어(Staff Engineer)
스태프 엔지니어는 단순히 시니어 엔지니어보다 개발을 잘 하는 사람이 아니다. 단일 팀보다는 상위 조직에서 일을 하거나 여러 팀에 기여하는 사람이다. 즉, 개인과 팀이 아닌 조직을 위한 사람이다.

<스태프 엔지니어>(윌라르소, 2021) 책에서 스태프 엔지니어의 원형을 4가지로 정의했다.
- 기술 책임자(Tech Lead)
- 복잡한 문제에 대해 한 팀 또는 여러 팀을 조정해 문제 해결
- 아키텍트(Architect)
- 복잡하거나 여러 팀에 영향을 주는 영역에서 기술적 방향, 품질, 접근 방식에 대한 설계 책임
- 해결사(Solver)
- 어려운 문제에 대해 실무적으로 깊이 관여해 적절한 해결책 제공
- 오른손(Right Hand)
- 복잡한 조직을 운영할 수 있는 권한을 갖고 비즈니스, 기술, 프로세스를 개선
개인의 성향에 따라 스태프 엔지니어의 타입이 달라진다. 스태프 엔지니어의 채용 공고는 위 4가지 타입의 원형을 모두 언급하기 때문에 스태프 엔지니어가 되기 위해 준비해야할 것이 불명확하다.
하지만 4가지 타입을 보면 공통적인 것이 '팀을 넘어서 조직의 성공에 가치를 두는 것'이다.
조직에 스태프 엔지니어는 왜 필요한가?
스포티파이는 교차 기능 조직 팀으로 자율성을 갖고 일을 하고 있다. 일을 명령받아 수행하는 것이 아니라 목표를 공유하고 자율적으로 토론, 협업하며 업무를 수행한다. 같은 목표를 공유한다는 점이 중요하다.
자율팀에 대한 트레이드오프로 각각의 팀이 중복된 코드, 라이브러리를 만들 수 있다. 상황에 따라 기술 표준화가 더욱 중요해진다.
예를 들어 안드로이드 개발을 자바에서 코틀린으로 마이그레이션한다고 하면 조직 단위에서 바꿀 사람이 필요하다. 이런 일들은 팀의 범위를 벗어나 조직 차원에서 이익을 이끌어내는 작업이다. 조직에서 이런 일을 이끌어내기 위해 스태프 엔지니어가 필요하다.
즉, 각각의 팀들이 팀내에서 목표를 갖고 업무를 진행할 때, 스태프 엔지니어는 팀들의 목표를 한 곳에 일치시켜 이니셔티브를 성공적으로 완료하는 역할이다. 이로써 조직의 이익을 추구하는 것이다.
개인의 성장 방향과 조직의 방향이 같기는 쉽지 않다. 더군다나 같은 조직에서 새로운 경험을 하기 어려울 수도 있다.
성장은 지속적인 여정이라 생각한다. 더 크거나 더 작은 조직으로 가는 것도 여정의 일부다. 여정을 반복하다보면 속도가 느려지거나 돌아가야할 수도 있는데 개개인이 원하는 방향에 대해 한번 고민을 먼저 해야한다. 성장 여정을 계속 하다보면 언젠가는 원하는 방향에 도착할 수 있을 것이다.
패션 이커머스 서비스의 아키텍처 성장 기록 - 이희창
전반적으로 29cm에서 모놀리식에서 MSA로 전환한 이야기를 다룬다.
모놀리식 아키텍처는 비즈니스의 모든 도메인과 로직이 하나의 애플리케이션에 담기는 구조다. 처음 시작하는 회사는 보통 모놀리식 아키텍처로 서비스를 구조한다. 모놀리식 아키텍처는 쉬운 개발과 배포, 간단한 테스트, 간편한 모니터링과 디버깅의 장점이 있다.
하지만 서비스가 잘 성장하고 있다면 모놀리식 아키텍처의 한계는 언젠가 찾아온다.
29cm의 경우에는 시스템 장애 빈도가 점차 증가했고, 대량의 트래픽을 감당하지 못했다. 코드의 배포 주기가 느려지며 요구사항의 추가 및 변경이 어려웠다.
이에 대한 원인으로 레거시 코드의 품질도 있겠지만 모놀리식 구조의 한계의 영향이 있다고 판단했다.
29cm는 그러다보니 2020년 8월에 MSA로 전환을 시도했다. MSA가 레거시 코드를 점진적으로 개선할 수 있으면서 확장성을 줄 수 있는 아키텍처라 판단했다.
MSA는 단점도 존재한다. 구현의 복잡도가 증가하며 테스트와 디버깅 비용이 증가한다. 대용량 트래픽 처리가 가능하긴 하지만 서비스간 API 호출로 지연도 발생하게 된다.
MSA로 전환할때는 점차 전환해야한다. 빠르게 전환하기 어려울 뿐만 아니라 장애 발생 가능성도 높다.
이후 29cm에서 실제 발생했던 장애와 해결책을 소개하며 설명한다.
'리뷰 > 컨퍼런스, 세미나 등 리뷰' 카테고리의 다른 글
| [컨퍼런스] if(kakao)dev2022 (2022/12/07~12/09) (0) | 2023.01.17 |
|---|---|
| [컨퍼런스] 우아콘(우아한형제들의 기술 콘퍼런스) (2022/10/19~10/21) (0) | 2022.11.15 |
| [컨퍼런스] NDC(Nexon Developer Conference) (2022/06/08~06/11) (0) | 2022.08.09 |
| [컨퍼런스] Google I/O (2022/05/11) (0) | 2022.05.21 |
| [컨퍼런스] AWS Innovate AI/ML Edition (2022/02/24) (0) | 2022.02.27 |
